批量执行远程命令的脚本 背景最近有机器需要进行检查,看上面的服务是否正常,需要执行大量的机器,可以拿到ip.list,以万为单位的,如果一个个去执行就非常的慢了这里我们采用一个脚本进行执行,就快很多了 相关脚本12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758 2025-06-18 系统管理 #批量执行
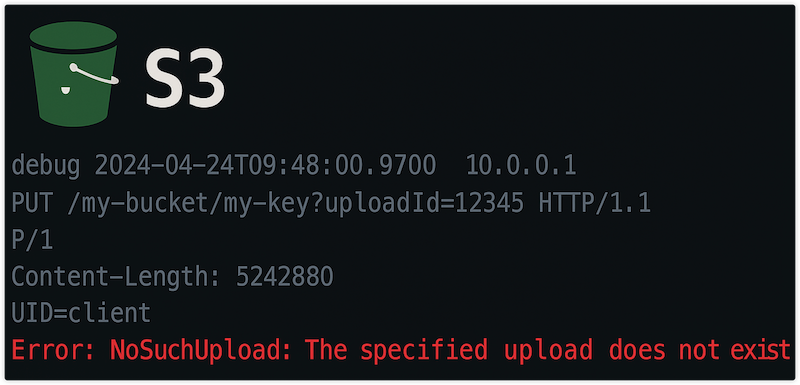
s3分段上传异常定位记录 背景内部定位一个分段上传的异常,原因是一个参数的设置异常,定位过程中用到了几个脚本,这里记录下 定位过程怀疑请求42min超时经过多次上传,观察到文件在上传42分钟左右的时候会提示失败了,初步怀疑是后台是否有超时参数,上传超过42分钟会失败 慢速上传验证这里通过一个s3cmd,上传一个相同大小的大文件,并且把时间控制到更长,超过42min 1time s3cmd put --limit-rate= 2025-06-17 存储相关 #ceph
测试路由转发最大连接数脚本 背景有一个场景下,路由器配置了端口转发,出现了一些端口响应问题,我们需要确定下这个环境的单个端口最大并发数目 方式是启动一个服务端,然后执行数目的长连接,检查最多可以连接到多少 测试脚本12345678910111213141516171819202122232425262728293031323334353637383940import asyncioimport sysasync def ha 2025-06-09
mysql数据库无法备份的问题 背景环境采用的是mysql的数据库版本为8.0.30,这个版本使用xtrabackup进行备份的时候,有个redo log异常的问题,新功能在增加减少列之后,再使用工具备份,工具就会判断异常,然后就不进行备份 我们备份一般是使用备节点进行备份,那么可以在出现了列相关的变动以后,在备节点上面操作库优化,然后再进行备份即可 注意操作修剪表之前停止备份,修剪完之后,开启备份 实践过程备份命令1xtrab 2025-06-04 系统管理 #数据库
mysql数据库重配置主从配置 背景线上一套环境之前配置了主从从配置,因为机器故障,进行了一次迁移,之前配置主从配置的时候,从节点配置的时候没有配置gtid模式,采用的是position模式,这个有个问题就是主从每次切换需要重新找到position,否则就会丢失切换区间的数据 本次故障后,进行一次完整导入,然后配置gtid模式,后续再切换的时候,就直接配置即可 注意这个是需要全量重配置的时候需要操作的步骤,如果配置了gtid模式 2025-06-04 系统管理 #数据库
使用percona-toolkit同步mysql表数据 背景做了主备mysql的配置以后,可能因为切换过程造成不一致的情况,这个时候可以处理的方式是全量导入再导出,这个有个问题就是操作的数据太多了我们只需要数据补全同步即可 mysql的同步是基于binlog的,如果没有记录的部分的数据,这个是无法同步的,就需要手动处理 或者就是两个数据库,定期手动同步到另外一个数据库,这个都可以使用这个工具 工具下载下载网址 https://www.percona. 2025-04-15 系统管理 #数据库
rbd块设备的id修改 背景看到有这个需求,具体碰到什么场景了不太清楚,之前做过rbd的重构的研究,既然能重构,那么修改应该是比重构还要简单一点的,我们具体看下怎么操作 数据结构分析rbd的元数据信息1234567891011121314151617181920212223242526272829303132[root@lab104 ~]# rbd create testrbd --size 1T[root@lab104 2025-04-10
tidb数据库的恢复操作 背景tidb数据库是多副本的一个集群数据库,类似ceph,三节点出现两节点的时候也是无法选举,以及内部数据的leader不同,会出现无法访问的情况,本篇就是基于这个来进行恢复的实践 三节点坏两个,做恢复 备份了一个节点数据,三个节点都坏了 这两个场景基本一致的 相关操作清理集群 1tiup cluster destroy tidb-test 关闭顺序 tidb tikv pd 初始化集 2025-04-09 数据库 #tidb
rgw的d3n功能配置 背景最近在看缓存相关,文件系统可以通过fscache加速,加速的效果就是读取的时候能够缓存,原理是在网关的地方加入一个高速缓存盘,这样在后续读取的时候,能够直接从缓存盘读取,这样能够减少与集群的交互,从而提供更大的性能,并且这个是缓存读取,所以数据安全性没有问题 rgw的d3n这个功能就是给rgw的网关加入了一个缓存盘,指定一个目录,然后能够缓存数据到目录 版本要求12[root@lab201 ~ 2025-04-02 存储相关 #ceph
kvm下的ceph主机启动io请求统计 背景假如一个主机存储在ceph里面,我们想统计下一次启动过程中的io读取的情况,那么可以通过下面的方法来统计启动时间也可以通过在宿主机里面去查看,通过日志这边要方便一点,无需登录到虚拟机内部 日志开启123456789101112131415[global]fsid = 4064c56e-c9ad-4b19-bf74-c4e291be5920mon_initial_members = lab104 2025-02-19