为什么只坏了一个盘集群无法读写
背景
我们拿到故障环境,看到环境就坏一个osd,但是环境还是处于卡着的状态,这个时候客户肯定会问,怎么就坏一个盘,还无法用了,不是都配置了冗余么
这个地方我们来分析下这个问题的原因,坏一个osd只是结果,不是过程,我们看下过程发生了哪些状况
中间过程
这个中间过程我们用图来说过程比较清晰一些
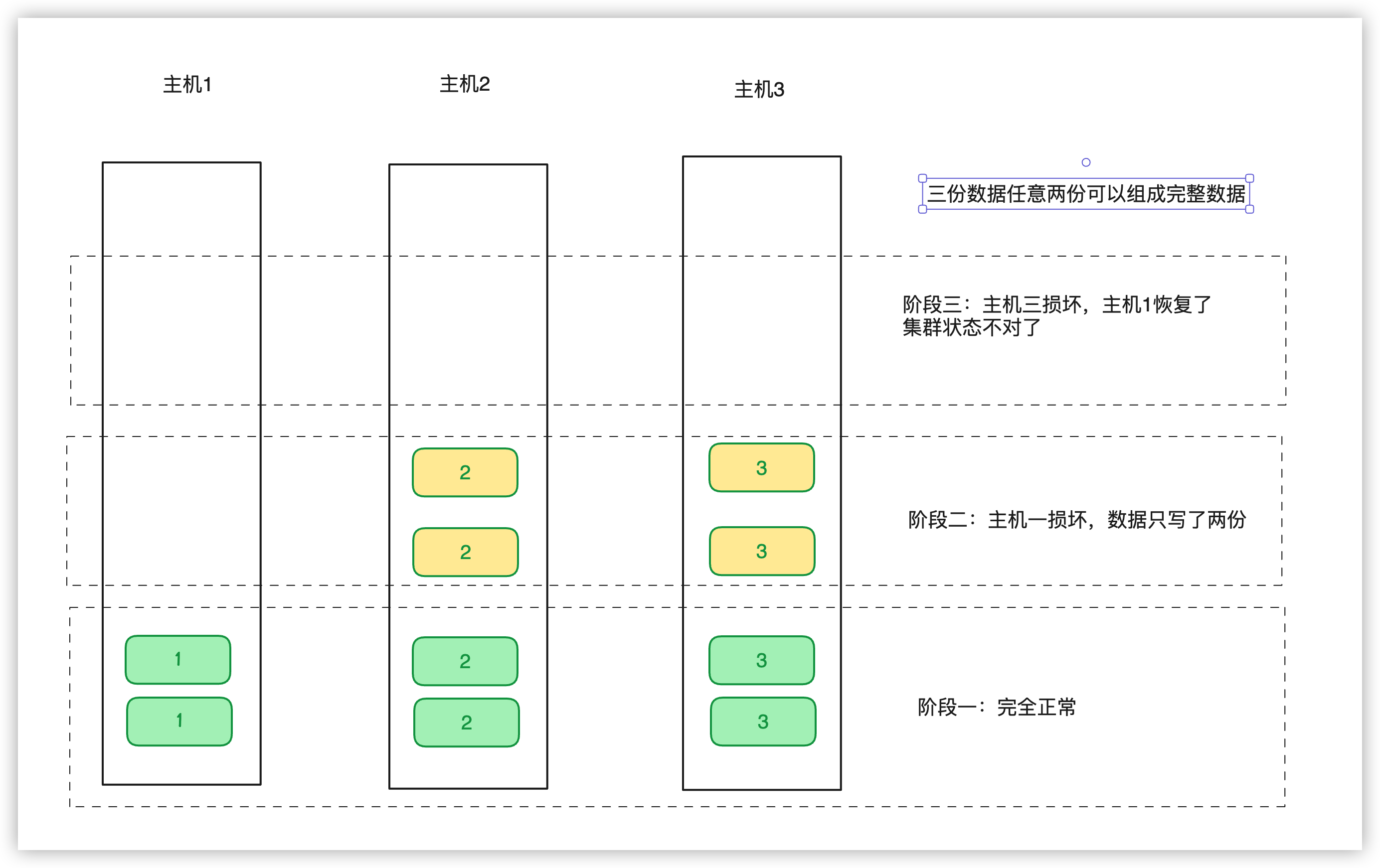
上面是时间线上的三个阶段的情况
阶段一:
数据完整,没有任何问题,数据写三份,分布到三台机器阶段二:
主机1sas卡出问题了,这个时候集群处于降级状态,数据只写了两份写到主机2,主机3,这个时候过了一段时间主机3突然又坏了,我们这个时候同时也发现主机1之前坏了,这个时候主机1启动起来,主机3是不可启动状态(磁盘异常无法恢复)阶段三:
ceph集群判断状态正常是需要至少能恢复的数据,也就是如果是三份(ec2+1),至少需要两份数据是完整的,这个时候集群才能读能写,到这个阶段我们可以看到,中间黄色部分的数据,因为主机3现在无法恢复,主机1之前故障了,这个只有一份数据2还在,三份数据只有1份了,这个时候集群自己是没法让自己正常的,因为主机3如果能启动起来,那么数据就还是完整的,集群内部也无法知道主机3是否能启动(也就是看到的pg的提示建议标记lost或者启动)
这个时候集群就处于异常了,需要人工处理
上面就是最终体现的现场的情况了,最终看到的是down一个osd,其实是因为down osd 之前,集群已经处于不正常状态了(注:现场发生了整机osddown和另外一个osddown ,发生的先后关系不影响上面的过程)

官方的解释就是,无法有完整的pg做恢复的时候 就是这个状态,集群中间状态又出第二个问题的时候,就会有这种情况出现了
处理方法
人工处理
- 方法一:
1、最好的办法是把主机3的最后坏的那个osd启动起来,能拉起来,那么数据还是完整的,写入的数据就都不丢 - 方法二:
另外一个办法就是,主机1和主机2强制标记状态,那么中间那部分黄色的数据就掉了,这个数据破坏多大,就是这个中间的时间差写的数据了 - 方法三(操作不确定性比较大,不建议):
看下主机3的pg是否可以全部导出,如果可以导出,可以导入到最新映射的地方,这样数据也能恢复
为什么只坏了一个盘集群无法读写
https://zphj1987.com/2024/12/04/为什么只坏了一个盘集群无法读写/