前言
ceph已经是一个比较成熟的开源的分布式存储了,从功能角度上来说,目前的功能基本能够覆盖大部分场景,而社区的工作基本上是在加入企业级的功能和易用性还有性能等方面在发力在,不管你是新手还是老手,都绕不开的一个问题就是crush,而crush是决定着数据的分布的,很多人并不理解为什么会有这个crush,这个算法到底是怎么去计算的,本篇是从更偏向用户层来对这个分布做一个解释,以及我们该怎么去动这个crush,本篇的内容不需要有代码开发能力,只需要稍加思考,都可以理解,剩下的就是你自己的选择了
所有的存储都离不开分布的问题,存储是不是做副本,副本是如何分布的都是有自己的一套逻辑的
这里拿gluster做例子,gluster的数据分布就是通过子卷来控制的,副本几,那么数据的子卷就是由几个组成,一个文件是默认落到一个子卷的,如果没做分片的话,然后所有的盘符的子卷组成了一整个的卷,数据是散列到子卷里面去的,这种子卷的组合是固定的,组合是通过命令的先后顺序来控制的,也就是数据的分布组合是固定的
而ceph的灵活之处在于把这种子卷的逻辑向下走了一层,通过一个pg的概念,以目录为结构做出很多这样的组合来,gluster是以磁盘(或者理解为固定目录)为粒度做brick,而ceph则是以可以飘动的pg来做分布,而pg的分布则可以通过人为的控制来实现我们的需求,好了,准备进入本篇的内容
探索过程
本次测试由于需要测试的模式有几种,需要的节点比较多,因此需要多做几个节点的集群,我采用的是虚拟主机的模式,这个跟实际的环境在crush层面是基本一致的,这里是为了说明一下,即使你没有很多机器,一样能够去模拟很多机器的情况,本篇就是在一台机器下完成了整个模拟的
本次crush的说明都是以副本二进行说明,副本三的情况是同理类比即可
###模式一:默认模式
如果你是新手,或者接触的ceph不久的话,我们来做ceph学习或者验证的时候,应该是准备了几台主机,然后根据官网文档或者各种教程,部署起来ceph,部署完了以后可以通过命令ceph osd tree来看到一个最基本的分布,这个是我们比较常规的模式,在环境小的时候,基本采用的是这个模式,我们来看下这种默认模式的情况
默认的情况是主机分组的,主机分组的意思是PG的主副本会分布到不同的主机上去,不会出现同一个PG的主副本在一台机器的情况,这样在出现主机级别的故障的时候,集群内还有副本在,这样数据就还是可以保证能够访问得到,主机级别的分组是默认的
先看下tree的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| [root@lab101 ~]
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 64.00000 root default
-2 8.00000 host lab101
0 2.00000 osd.0 up 1.00000 1.00000
1 2.00000 osd.1 up 1.00000 1.00000
2 2.00000 osd.2 up 1.00000 1.00000
3 2.00000 osd.3 up 1.00000 1.00000
-3 8.00000 host lab102
4 2.00000 osd.4 up 1.00000 1.00000
5 2.00000 osd.5 up 1.00000 1.00000
6 2.00000 osd.6 up 1.00000 1.00000
7 2.00000 osd.7 up 1.00000 1.00000
-4 8.00000 host lab103
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
10 2.00000 osd.10 up 1.00000 1.00000
11 2.00000 osd.11 up 1.00000 1.00000
-5 8.00000 host lab104
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
14 2.00000 osd.14 up 1.00000 1.00000
15 2.00000 osd.15 up 1.00000 1.00000
-6 8.00000 host lab105
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
18 2.00000 osd.18 up 1.00000 1.00000
19 2.00000 osd.19 up 1.00000 1.00000
-7 8.00000 host lab106
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
22 2.00000 osd.22 up 1.00000 1.00000
23 2.00000 osd.23 up 1.00000 1.00000
-8 8.00000 host lab107
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
26 2.00000 osd.26 up 1.00000 1.00000
27 2.00000 osd.27 up 1.00000 1.00000
-9 8.00000 host lab108
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
30 2.00000 osd.30 up 1.00000 1.00000
31 2.00000 osd.31 up 1.00000 1.00000
|
我们看下crush rule的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| [root@lab101 cephsankey]
{
"rule_id": 0,
"rule_name": "replicated_ruleset",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
|
这个意思是从default为入口,把PG分布到不同的host里面去,默认就是这个,也就不涉及到编辑crush_map的问题,编辑的部分后面会讲
现在就有一个客户经常会问到的问题了,只有副本2,如果同时关闭两台机器,数据是不是就访问不到了,如果按照目前的默认自由分布来看,散列的分布情况下,必然会有数据的主副本PG是在你关闭的两主机上的,数量不会很多,但是肯定会有,这样基本就是百分百的概率出现有数据访问不到了
这个怎么解决,还是有办法改善这个情况的,这个就用到了分布式软件里面经常用到的概念rack分组,一般在设计分布式软件的时候,在测试高可用的时候,会去尝试测试关闭整个机架来测试服务的可用性,在ceph里面,如果你的机器并不是很多,只有几个物理机器,那么这里提到的机架是可以是逻辑上的,也就是从概率上面去减小必定损坏前提情况下的数据丢失可能性,这个就是下一个模式要讲到的,rack分组
模式二:rack分组模式
rack分组的模式就是在主机分组上面增加一层rack,然后让pg的主副本是分布到不同的rack下面的我们看下具体的情况
先编辑好tree的,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| [root@lab101 ~]
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 64.00000 root default
-10 16.00000 rack rack1
-2 8.00000 host lab101
0 2.00000 osd.0 up 1.00000 1.00000
1 2.00000 osd.1 up 1.00000 1.00000
2 2.00000 osd.2 up 1.00000 1.00000
3 2.00000 osd.3 up 1.00000 1.00000
-3 8.00000 host lab102
4 2.00000 osd.4 up 1.00000 1.00000
5 2.00000 osd.5 up 1.00000 1.00000
6 2.00000 osd.6 up 1.00000 1.00000
7 2.00000 osd.7 up 1.00000 1.00000
-11 16.00000 rack rack2
-4 8.00000 host lab103
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
10 2.00000 osd.10 up 1.00000 1.00000
11 2.00000 osd.11 up 1.00000 1.00000
-5 8.00000 host lab104
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
14 2.00000 osd.14 up 1.00000 1.00000
15 2.00000 osd.15 up 1.00000 1.00000
-12 16.00000 rack rack3
-6 8.00000 host lab105
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
18 2.00000 osd.18 up 1.00000 1.00000
19 2.00000 osd.19 up 1.00000 1.00000
-7 8.00000 host lab106
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
22 2.00000 osd.22 up 1.00000 1.00000
23 2.00000 osd.23 up 1.00000 1.00000
-13 16.00000 rack rack4
-8 8.00000 host lab107
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
26 2.00000 osd.26 up 1.00000 1.00000
27 2.00000 osd.27 up 1.00000 1.00000
-9 8.00000 host lab108
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
30 2.00000 osd.30 up 1.00000 1.00000
31 2.00000 osd.31 up 1.00000 1.00000
|
创建crush rule
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| 创建一个规则
[root@lab101 ~]
查看规则
[root@lab101 ~]
{
"rule_id": 1,
"rule_name": "replicated_rack",
"ruleset": 1,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "rack"
},
{
"op": "emit"
}
]
}
设置存储池到这个规则
[root@lab101 ~]
set pool 1 crush_ruleset to 1
|
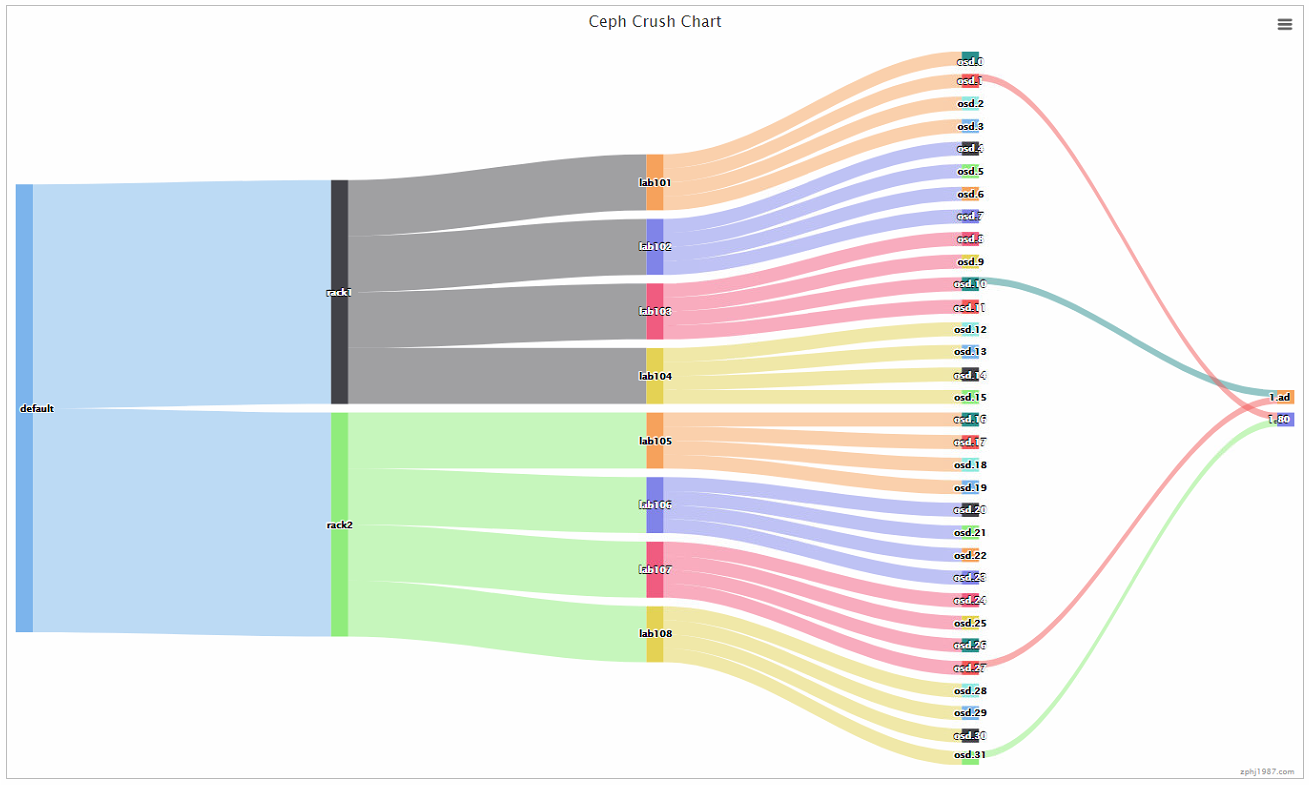
我们看下pg的分布情况,每个pg的正副本是分布到不同rack的,没有出现主副本在同一个rack下面的两个主机里面的情况
可以看到我们这里是8台主机,分了4个rack,这个里面可以比之前主机分组好的情况是,如果down的是同一个rack的两台主机,那么这个情况的数据是不会掉的,因为数据在其他的rack里面肯定会有一份的,可以看到在当前的环境下面,有四种情况的主机组合在down的时候不会掉数据,我们是做了四个rack,这里我们来看下如果只做两个rack的情况,跟做四个rack的情况有什么区别呢?这个也是写本篇文章的时候才发现的一个结论
看下如果两个rack的情况下的tree
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| [root@lab101 ~]
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 64.00000 root default
-10 32.00000 rack rack1
-2 8.00000 host lab101
0 2.00000 osd.0 up 1.00000 1.00000
1 2.00000 osd.1 up 1.00000 1.00000
2 2.00000 osd.2 up 1.00000 1.00000
3 2.00000 osd.3 up 1.00000 1.00000
-3 8.00000 host lab102
4 2.00000 osd.4 up 1.00000 1.00000
5 2.00000 osd.5 up 1.00000 1.00000
6 2.00000 osd.6 up 1.00000 1.00000
7 2.00000 osd.7 up 1.00000 1.00000
-4 8.00000 host lab103
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
10 2.00000 osd.10 up 1.00000 1.00000
11 2.00000 osd.11 up 1.00000 1.00000
-5 8.00000 host lab104
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
14 2.00000 osd.14 up 1.00000 1.00000
15 2.00000 osd.15 up 1.00000 1.00000
-11 32.00000 rack rack2
-6 8.00000 host lab105
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
18 2.00000 osd.18 up 1.00000 1.00000
19 2.00000 osd.19 up 1.00000 1.00000
-7 8.00000 host lab106
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
22 2.00000 osd.22 up 1.00000 1.00000
23 2.00000 osd.23 up 1.00000 1.00000
-8 8.00000 host lab107
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
26 2.00000 osd.26 up 1.00000 1.00000
27 2.00000 osd.27 up 1.00000 1.00000
-9 8.00000 host lab108
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
30 2.00000 osd.30 up 1.00000 1.00000
31 2.00000 osd.31 up 1.00000 1.00000
|
rule还是不变,不做调整
可以看到pg是分布到不同的rack的,这个时候down机的组合是有12个的,而上面分4个rack的时候,down机的组合是4个,组合越多,代表着,在一定出现问题的情况下,数据掉的概率越低,组合数如下图所示,可以看的比较清楚
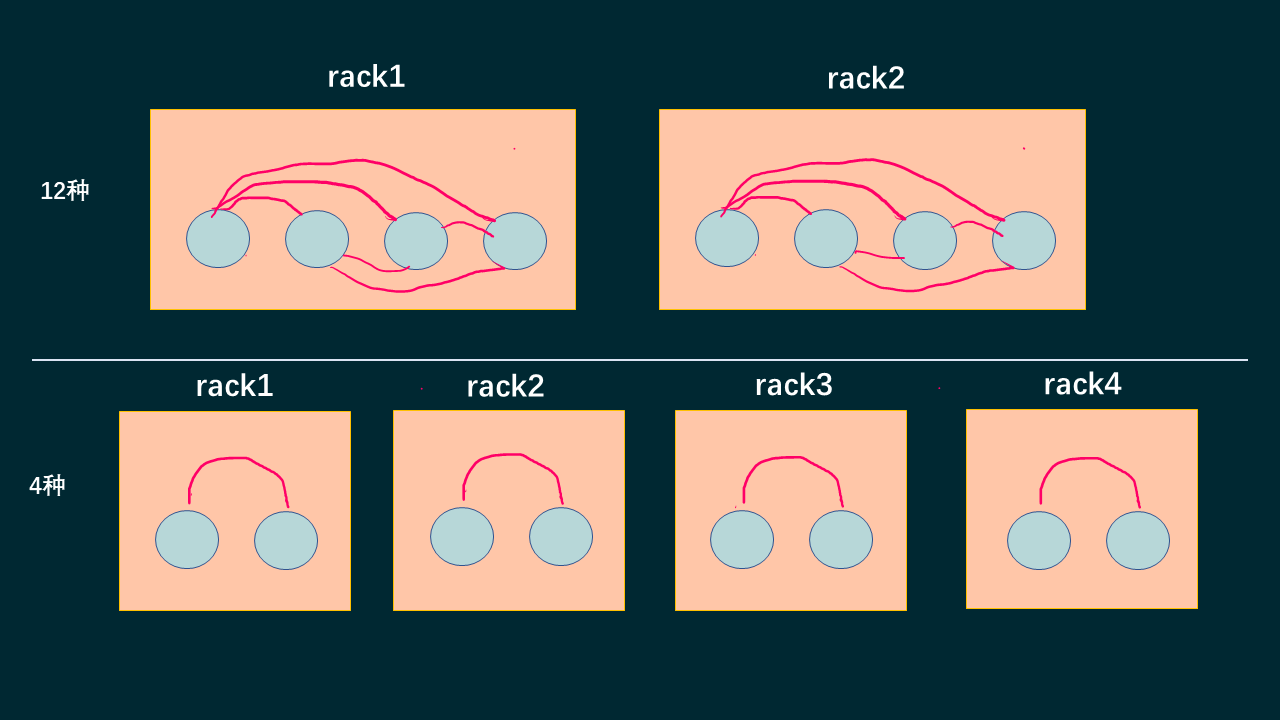
所以可以得出在目前的场景下面的一个结论,副本2的时候,分两个rack能够在只down两台机器的情况下,得到最大的可用性
我们已经加入了rack的分组形式了,那么还有什么更复杂高级的控制么,那肯定是有的,这个搞法我也是在曾经一个项目上面想到的,并成功的应用到那个生产环境了,我给这个方式起了个通俗名称叫PG分流
模式三:PG分流
通过上面的各种图的走向,应该会有一种概念可以形成,就是可以把上面的理解为一个水源往下流去,中间的各种通道就是输水管道,我们做的工作的目的也都是在管道出现阻塞的时候,水源仍然能够往下走去,不会出现断流的情况,为了保证这个的可用性,就有了副本去提高可用性,通过rack,来减小破坏出现的时候的影响,那么我们还有一种做法就是,让整个PG流向一个区域,让另一个PG流向另一个区域,这样做的好处是减小copy set,关于减少copyset的好处,之前有篇文章已经介绍过了,本篇就不去分析了,直接操作
tree是不用动的,还是上面的rack模式下的tree,需要动的是crush rule的
1
2
3
4
5
6
7
8
9
10
| rule replicated_rack {
ruleset 1
type replicated
min_size 1
max_size 10
step take default
step choose firstn 1 type rack
step chooseleaf firstn 0 type host
step emit
}
|
看下pg分布的图
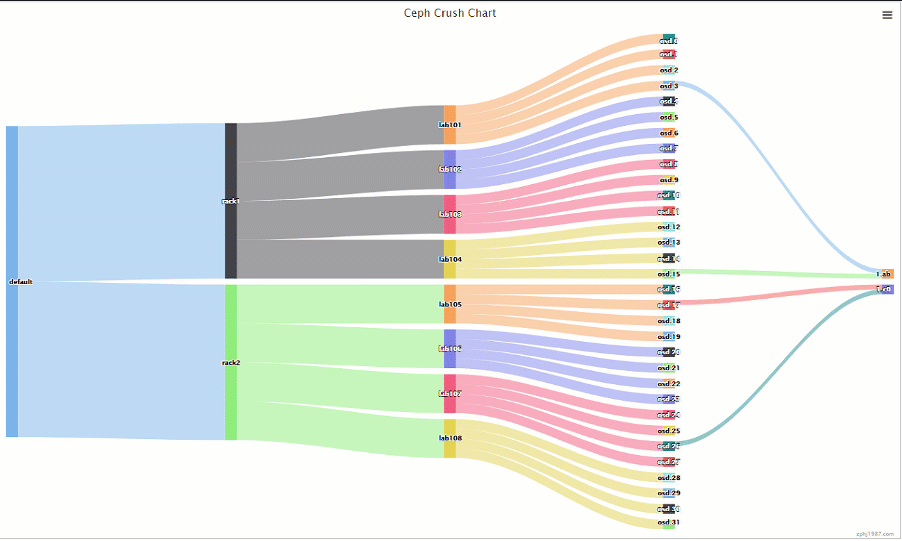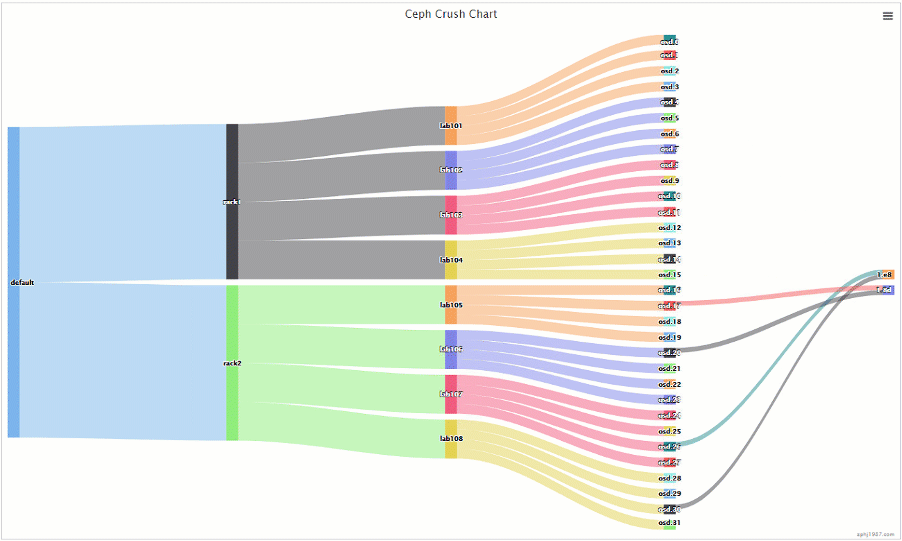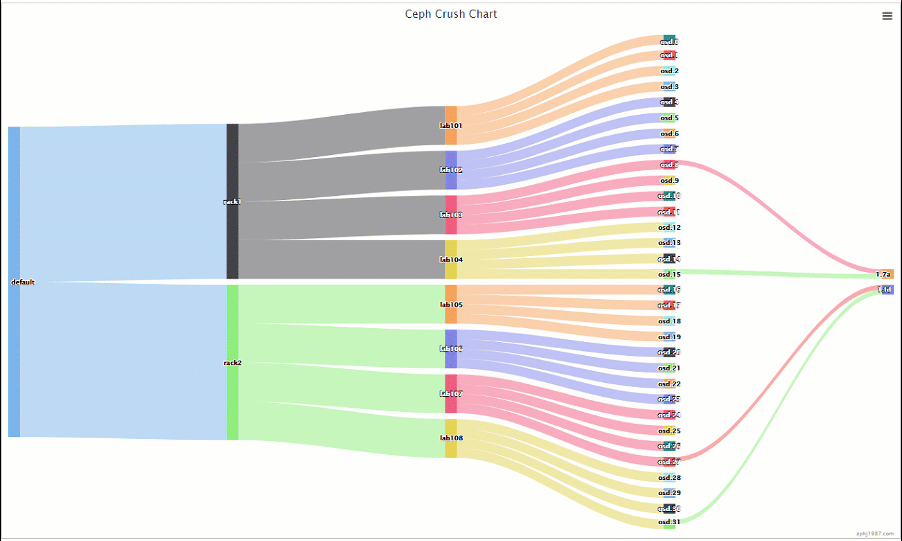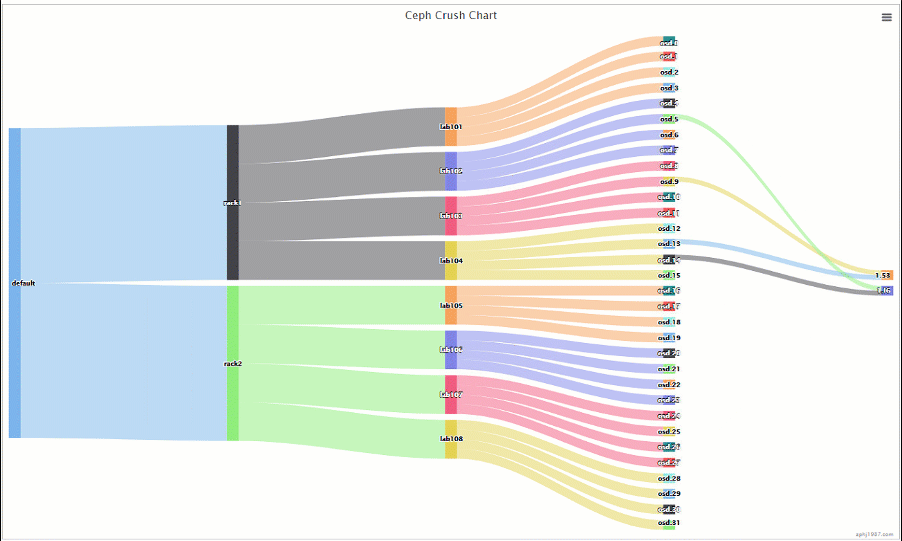
可以看到PG的主副本是在一个rack里面的,这个时候每个rack实际含有的PG只有集群一半的PG,而且每个主机只跟自己rack内的主机做交互的,这样在海量的机器的时候,能够减少不少的通信交互,也少了IO碰撞的情况出现
这样做只是减少了主机的交互,并且可用性上面反而提高了,我们看下
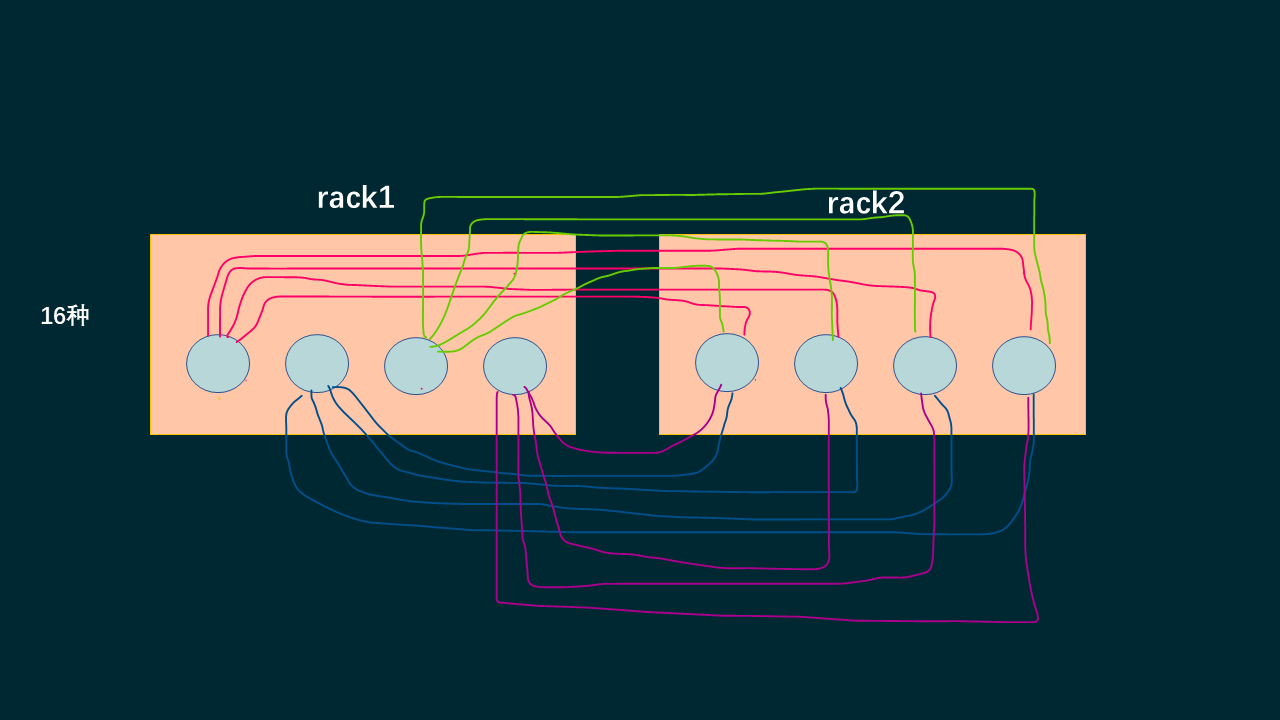
可以看到现在有16组的组合可以保证down机不掉数据
我们看到在rack分流以后,实际上是按的主机分组的,这个时候我们可以进一步的提高这个可用性,在下面再做一层的控制,做一个chassis的分组,这个也是ceph里面含有chassis分组标签,正好也是在rack之下
我们先编辑好map如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| [root@lab101 ~]
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 64.00000 root default
-10 32.00000 rack rack1
-12 16.00000 chassis chassis1
-2 8.00000 host lab101
0 2.00000 osd.0 up 1.00000 1.00000
1 2.00000 osd.1 up 1.00000 1.00000
2 2.00000 osd.2 up 1.00000 1.00000
3 2.00000 osd.3 up 1.00000 1.00000
-3 8.00000 host lab102
4 2.00000 osd.4 up 1.00000 1.00000
5 2.00000 osd.5 up 1.00000 1.00000
6 2.00000 osd.6 up 1.00000 1.00000
7 2.00000 osd.7 up 1.00000 1.00000
-13 16.00000 chassis chassis2
-4 8.00000 host lab103
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
10 2.00000 osd.10 up 1.00000 1.00000
11 2.00000 osd.11 up 1.00000 1.00000
-5 8.00000 host lab104
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
14 2.00000 osd.14 up 1.00000 1.00000
15 2.00000 osd.15 up 1.00000 1.00000
-11 32.00000 rack rack2
-14 16.00000 chassis chassis3
-6 8.00000 host lab105
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
18 2.00000 osd.18 up 1.00000 1.00000
19 2.00000 osd.19 up 1.00000 1.00000
-7 8.00000 host lab106
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
22 2.00000 osd.22 up 1.00000 1.00000
23 2.00000 osd.23 up 1.00000 1.00000
-15 16.00000 chassis chassis4
-8 8.00000 host lab107
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
26 2.00000 osd.26 up 1.00000 1.00000
27 2.00000 osd.27 up 1.00000 1.00000
-9 8.00000 host lab108
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
30 2.00000 osd.30 up 1.00000 1.00000
31 2.00000 osd.31 up 1.00000 1.00000
|
编辑crush_rule
1
2
3
4
5
6
7
8
9
10
| rule replicated_rack {
ruleset 1
type replicated
min_size 1
max_size 10
step take default
step choose firstn 1 type rack
step chooseleaf firstn 0 type chassis
step emit
}
|
可以看到pg的主副本是在单个rack里面的,而主本副本则是在两个chassis里面的,我们再来看下可用性
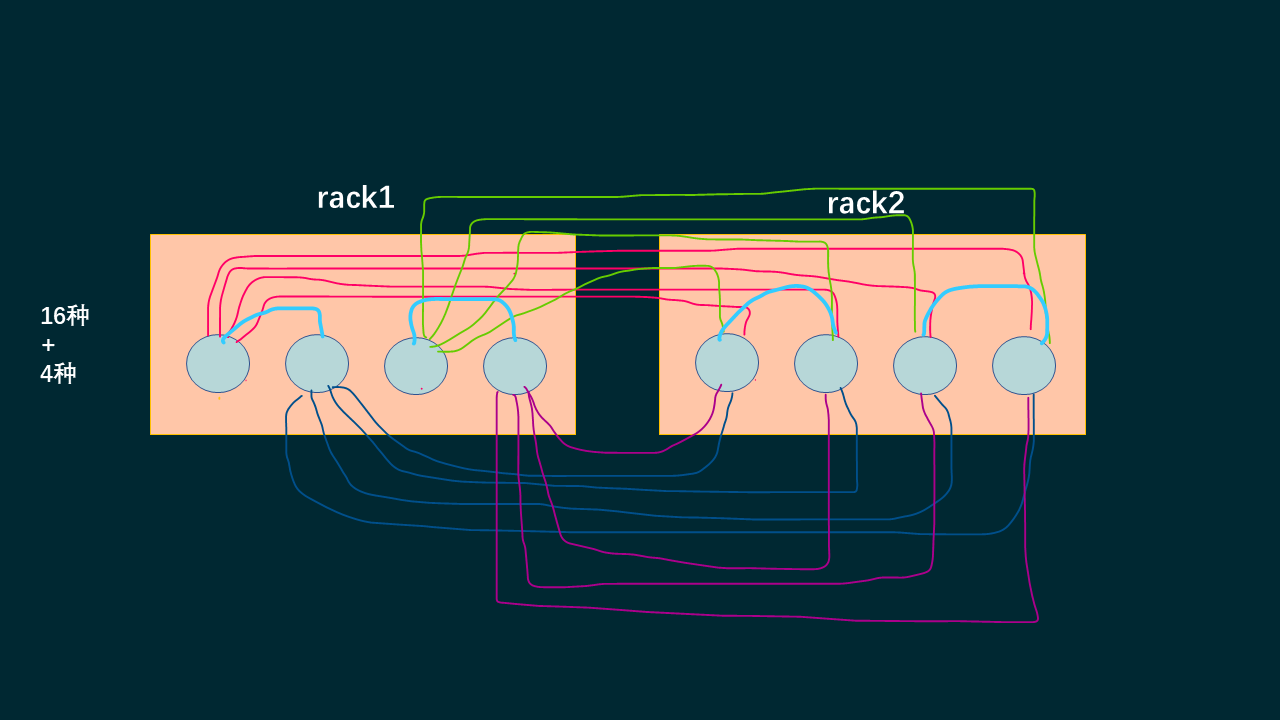
增加了chassis后,我们关闭chassis也不会出现数据丢失,这样又增加了四个组合,到现在达到了20种组合
可以看到在并没有改变硬件的情况下,通过逻辑的控制,增加了20种down机模式下不会掉数据的情况,虽然我们无法避免所有的情况的掉数据,但是通过一些改变增加了安全性,这个也是可以的
有的时候我们为了性能会上ssd,但是全部上ssd某些情况下,又觉得划不来,而读取的时候,数据是在主本上的,就跟副本没什么关系了,然后就会产生一种特殊的省成本的需求了,我想主本存在ssd上面,副本存在sata上面,容量不用担心,以ssd的为准,省了一个ssd的钱,如果是读的场景,这个更好了,那么作为灵活的crush,当然是可以支撑这种比较特殊的需求了,我们看下下面的模式
###模式四:sata-ssd组合
这个模式下的组合是主本存储在ssd上面,副本存储在sata上面,每台机器有sata也有ssd,我们看下我的这个环境的,假设8台机器的,每台4个osd里面较小id的是ssd的磁盘,较大的是id的是sata盘的
先编辑map,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| [root@lab101 ~]
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 64.00000 root default
-10 32.00000 rack rack1
-12 8.00000 chassis chassis1
-16 4.00000 host lab101-ssd
0 2.00000 osd.0 up 1.00000 1.00000
1 2.00000 osd.1 up 1.00000 1.00000
-25 4.00000 host lab102-sata
6 2.00000 osd.6 up 1.00000 0
7 2.00000 osd.7 up 1.00000 0
-13 8.00000 chassis chassis2
-17 4.00000 host lab102-ssd
4 2.00000 osd.4 up 1.00000 1.00000
5 2.00000 osd.5 up 1.00000 1.00000
-26 4.00000 host lab103-sata
10 2.00000 osd.10 up 1.00000 0
11 2.00000 osd.11 up 1.00000 0
-14 8.00000 chassis chassis3
-18 4.00000 host lab103-ssd
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
-27 4.00000 host lab104-sata
14 2.00000 osd.14 up 1.00000 0
15 2.00000 osd.15 up 1.00000 0
-15 8.00000 chassis chassis4
-19 4.00000 host lab104-ssd
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
-28 4.00000 host lab105-sata
18 2.00000 osd.18 up 1.00000 0
19 2.00000 osd.19 up 1.00000 0
-11 32.00000 rack rack2
-32 8.00000 chassis chassis5
-20 4.00000 host lab105-ssd
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
-29 4.00000 host lab106-sata
22 2.00000 osd.22 up 1.00000 0
23 2.00000 osd.23 up 1.00000 0
-33 8.00000 chassis chassis6
-21 4.00000 host lab106-ssd
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
-30 4.00000 host lab107-sata
26 2.00000 osd.26 up 1.00000 0
27 2.00000 osd.27 up 1.00000 0
-34 8.00000 chassis chassis7
-22 4.00000 host lab107-ssd
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
-31 4.00000 host lab108-sata
30 2.00000 osd.30 up 1.00000 0
31 2.00000 osd.31 up 1.00000 0
-35 8.00000 chassis chassis8
-23 4.00000 host lab108-ssd
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
-24 4.00000 host lab101-sata
2 2.00000 osd.2 up 1.00000 0
3 2.00000 osd.3 up 1.00000 0
|
crushmap编辑到如下:
1
2
3
4
5
6
7
8
9
10
11
| rule replicated_rack {
ruleset 1
type replicated
min_size 1
max_size 10
step take default
step choose firstn 1 type rack
step choose firstn 1 type chassis
step chooseleaf firstn 0 type host
step emit
}
|
上面的做组合的时候是交叉固定组合的,1机器ssd跟2机器的sata,2机器ssd跟3机器的sata,然后通过ceph osd primary-affinity来控制主本在ssd上面,我们看下我们的动图
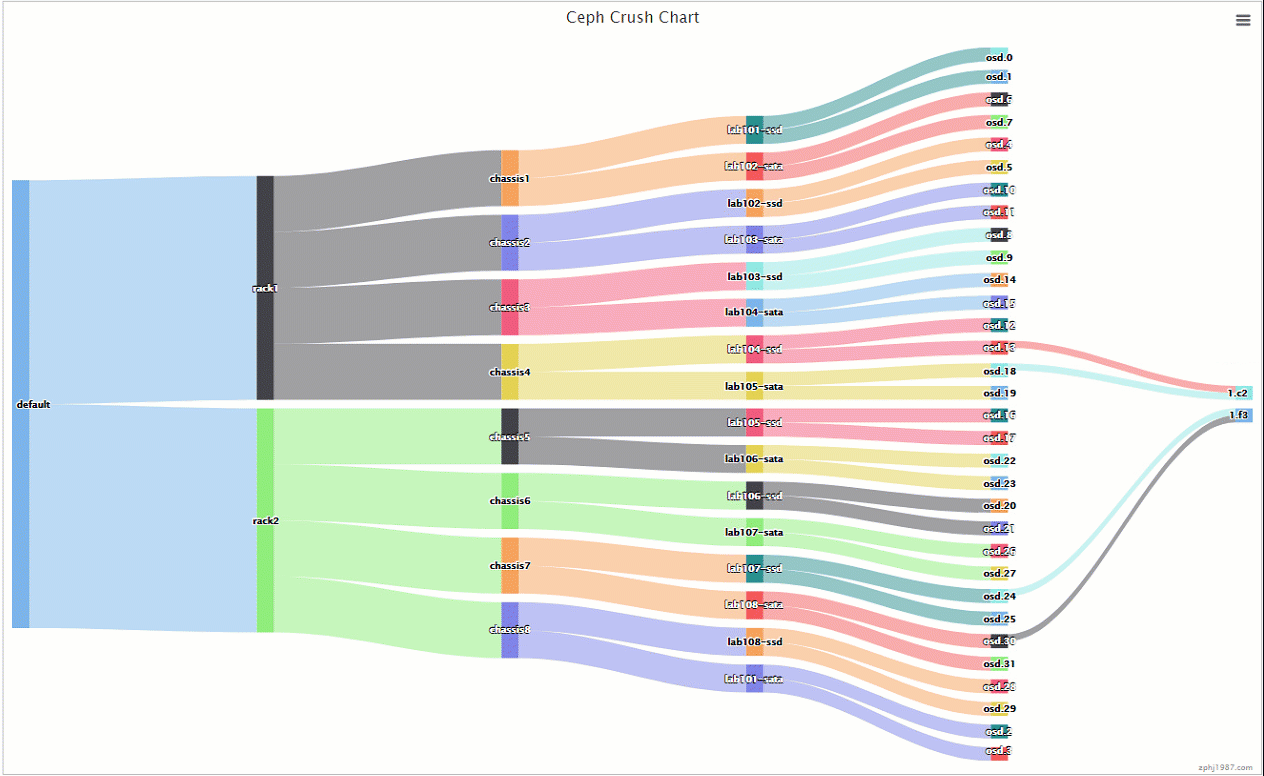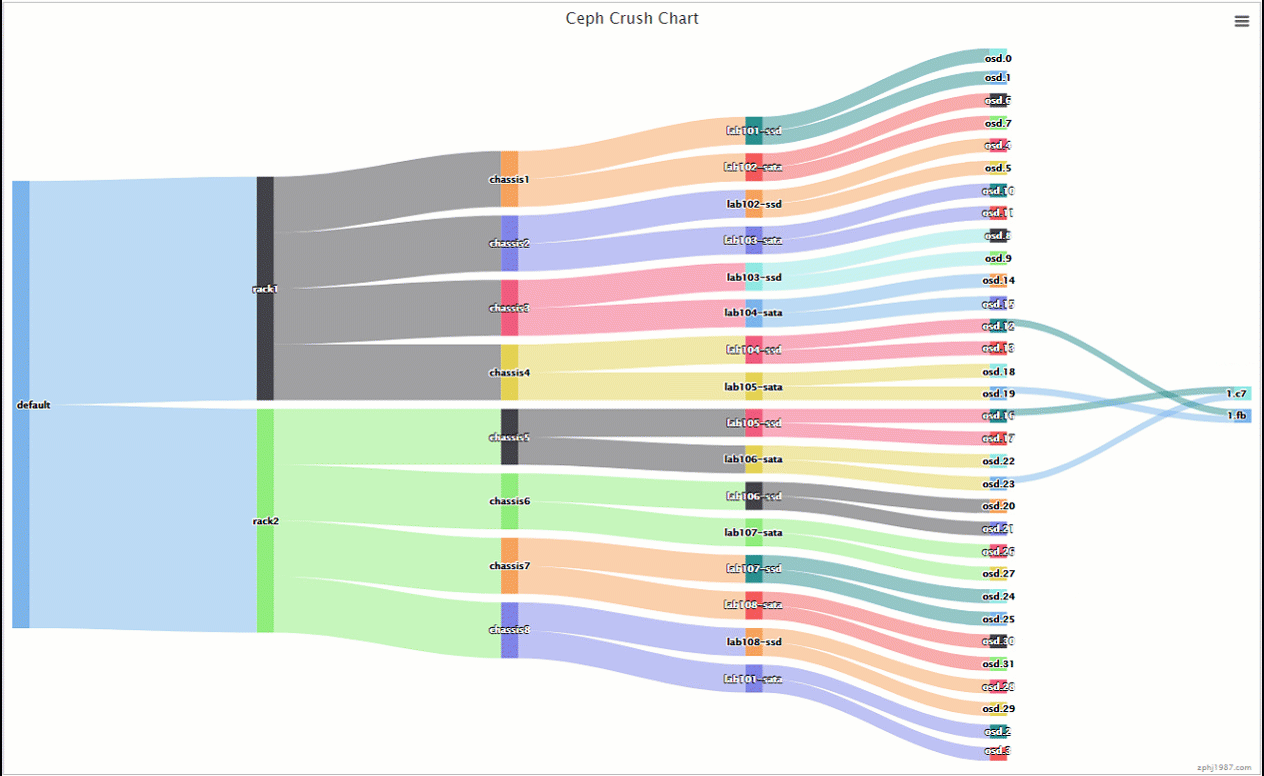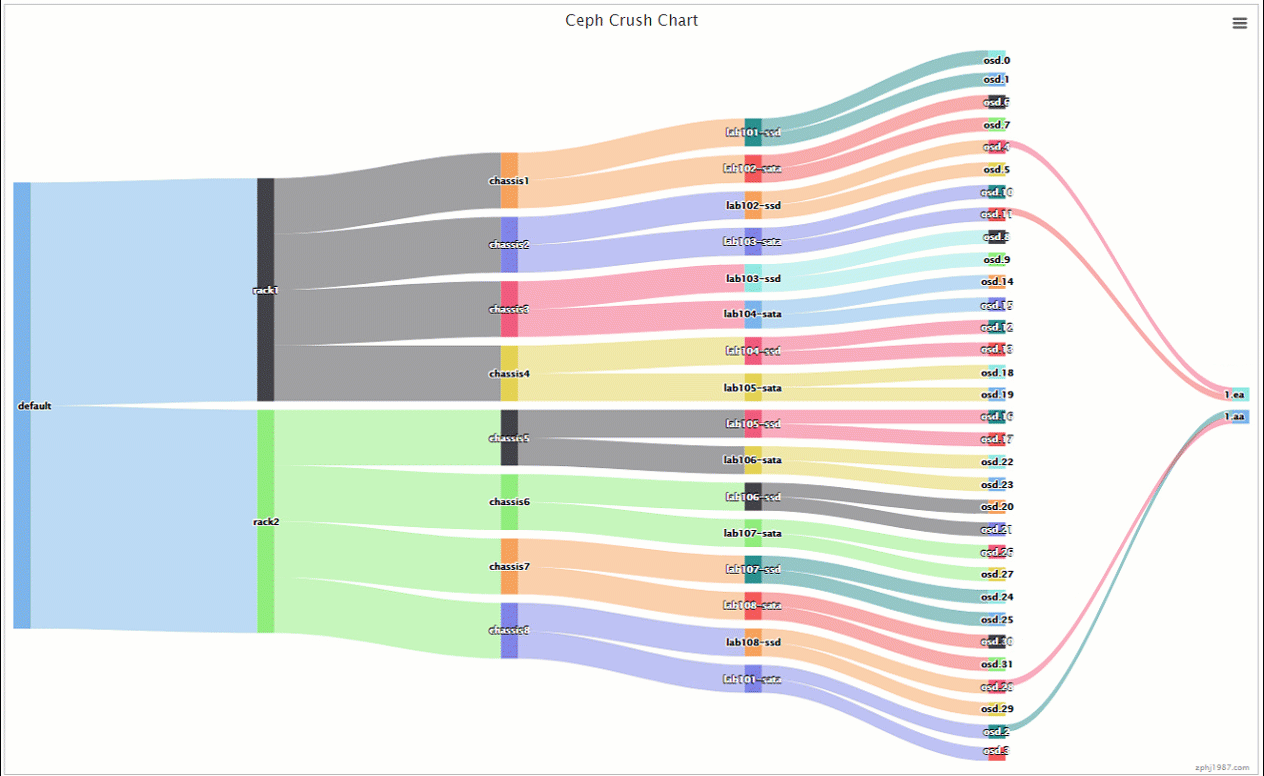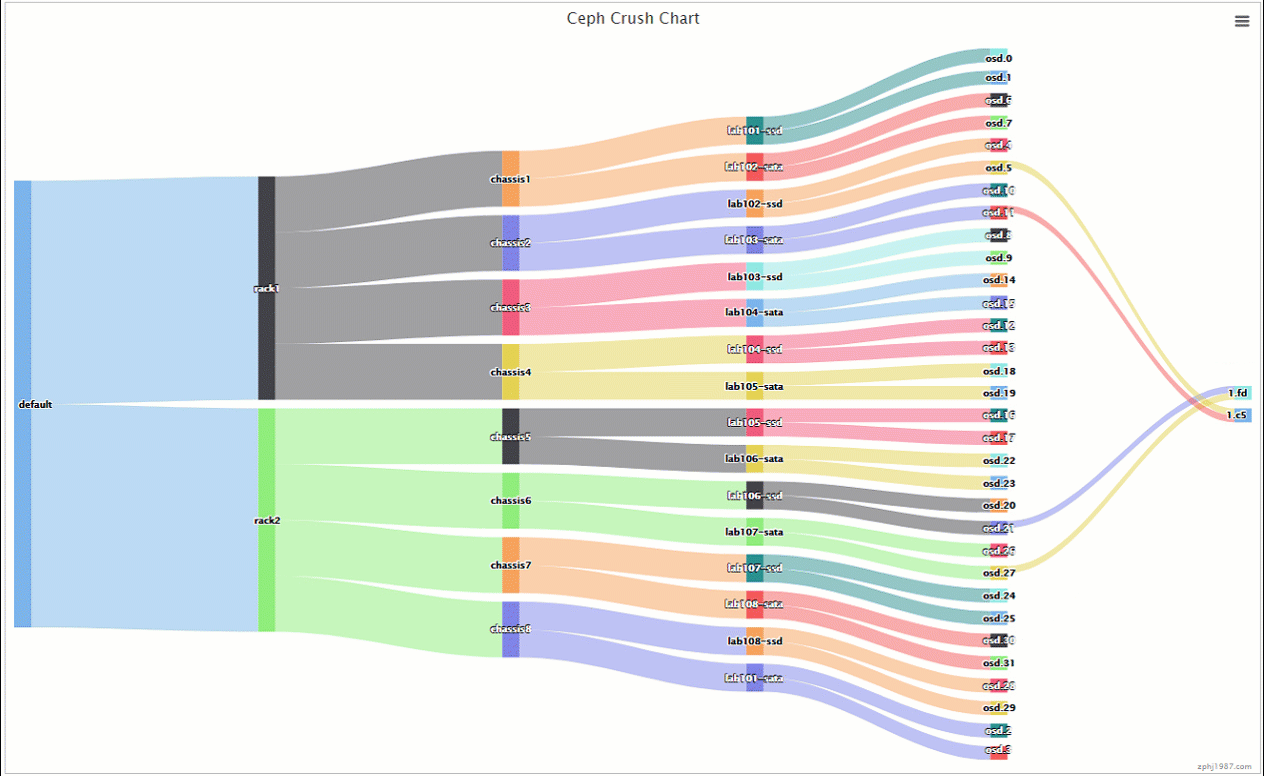
可以看到数据主本在ssd副本在sata了,但是这里可能会提出一个问题,就是这个组合数目是不是太少了,每个ssd的虚拟主机只跟一个进行组合,我想增加点多样性可以么,这里可以这么操作,rack分流的我们继续保持不变,这里只用增加每个rack里面的组合就行了,我们编辑tree如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
| [root@lab101 ~]
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 192.00000 root default
-10 96.00000 rack rack1
-2 8.00000 chassis chassis-lab101-ssd-1
-16 4.00000 host lab101-ssd
0 2.00000 osd.0 up 1.00000 1.00000
1 2.00000 osd.1 up 1.00000 1.00000
-25 4.00000 host lab102-sata
6 2.00000 osd.6 up 1.00000 0
7 2.00000 osd.7 up 1.00000 0
-3 8.00000 chassis chassis-lab101-ssd-2
-16 4.00000 host lab101-ssd
0 2.00000 osd.0 up 1.00000 1.00000
1 2.00000 osd.1 up 1.00000 1.00000
-26 4.00000 host lab103-sata
10 2.00000 osd.10 up 1.00000 0
11 2.00000 osd.11 up 1.00000 0
-4 8.00000 chassis chassis-lab101-ssd-3
-16 4.00000 host lab101-ssd
0 2.00000 osd.0 up 1.00000 1.00000
1 2.00000 osd.1 up 1.00000 1.00000
-27 4.00000 host lab104-sata
14 2.00000 osd.14 up 1.00000 0
15 2.00000 osd.15 up 1.00000 0
-5 8.00000 chassis chassis-lab102-ssd-1
-17 4.00000 host lab102-ssd
4 2.00000 osd.4 up 1.00000 1.00000
5 2.00000 osd.5 up 1.00000 1.00000
-26 4.00000 host lab103-sata
10 2.00000 osd.10 up 1.00000 0
11 2.00000 osd.11 up 1.00000 0
-8 8.00000 chassis chassis-lab103-ssd-1
-18 4.00000 host lab103-ssd
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
-27 4.00000 host lab104-sata
14 2.00000 osd.14 up 1.00000 0
15 2.00000 osd.15 up 1.00000 0
-9 8.00000 chassis chassis-lab104-ssd-1
-19 4.00000 host lab104-ssd
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
-24 4.00000 host lab101-sata
2 2.00000 osd.2 up 1.00000 0
3 2.00000 osd.3 up 1.00000 0
-6 8.00000 chassis chassis-lab102-ssd-2
-17 4.00000 host lab102-ssd
4 2.00000 osd.4 up 1.00000 1.00000
5 2.00000 osd.5 up 1.00000 1.00000
-27 4.00000 host lab104-sata
14 2.00000 osd.14 up 1.00000 0
15 2.00000 osd.15 up 1.00000 0
-40 8.00000 chassis chassis-lab103-ssd-2
-18 4.00000 host lab103-ssd
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
-24 4.00000 host lab101-sata
2 2.00000 osd.2 up 1.00000 0
3 2.00000 osd.3 up 1.00000 0
-41 8.00000 chassis chassis-lab104-ssd-2
-19 4.00000 host lab104-ssd
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
-25 4.00000 host lab102-sata
6 2.00000 osd.6 up 1.00000 0
7 2.00000 osd.7 up 1.00000 0
-7 8.00000 chassis chassis-lab102-ssd-3
-17 4.00000 host lab102-ssd
4 2.00000 osd.4 up 1.00000 1.00000
5 2.00000 osd.5 up 1.00000 1.00000
-24 4.00000 host lab101-sata
2 2.00000 osd.2 up 1.00000 0
3 2.00000 osd.3 up 1.00000 0
-46 8.00000 chassis chassis-lab103-ssd-3
-18 4.00000 host lab103-ssd
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
-25 4.00000 host lab102-sata
6 2.00000 osd.6 up 1.00000 0
7 2.00000 osd.7 up 1.00000 0
-47 8.00000 chassis chassis-lab104-ssd-3
-19 4.00000 host lab104-ssd
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
-26 4.00000 host lab103-sata
10 2.00000 osd.10 up 1.00000 0
11 2.00000 osd.11 up 1.00000 0
-11 96.00000 rack rack2
-36 8.00000 chassis chassis-lab105-ssd-1
-20 4.00000 host lab105-ssd
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
-29 4.00000 host lab106-sata
22 2.00000 osd.22 up 1.00000 0
23 2.00000 osd.23 up 1.00000 0
-37 8.00000 chassis chassis-lab106-ssd-1
-21 4.00000 host lab106-ssd
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
-30 4.00000 host lab107-sata
26 2.00000 osd.26 up 1.00000 0
27 2.00000 osd.27 up 1.00000 0
-38 8.00000 chassis chassis-lab107-ssd-1
-22 4.00000 host lab107-ssd
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
-31 4.00000 host lab108-sata
30 2.00000 osd.30 up 1.00000 0
31 2.00000 osd.31 up 1.00000 0
-39 8.00000 chassis chassis-lab108-ssd-1
-23 4.00000 host lab108-ssd
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
-28 4.00000 host lab105-sata
18 2.00000 osd.18 up 1.00000 0
19 2.00000 osd.19 up 1.00000 0
-42 8.00000 chassis chassis-lab105-ssd-2
-20 4.00000 host lab105-ssd
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
-30 4.00000 host lab107-sata
26 2.00000 osd.26 up 1.00000 0
27 2.00000 osd.27 up 1.00000 0
-43 8.00000 chassis chassis-lab106-ssd-2
-21 4.00000 host lab106-ssd
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
-31 4.00000 host lab108-sata
30 2.00000 osd.30 up 1.00000 0
31 2.00000 osd.31 up 1.00000 0
-44 8.00000 chassis chassis-lab107-ssd-2
-22 4.00000 host lab107-ssd
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
-28 4.00000 host lab105-sata
18 2.00000 osd.18 up 1.00000 0
19 2.00000 osd.19 up 1.00000 0
-45 8.00000 chassis chassis-lab108-ssd-2
-23 4.00000 host lab108-ssd
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
-29 4.00000 host lab106-sata
22 2.00000 osd.22 up 1.00000 0
23 2.00000 osd.23 up 1.00000 0
-48 8.00000 chassis chassis-lab105-ssd-3
-20 4.00000 host lab105-ssd
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
-31 4.00000 host lab108-sata
30 2.00000 osd.30 up 1.00000 0
31 2.00000 osd.31 up 1.00000 0
-49 8.00000 chassis chassis-lab106-ssd-3
-21 4.00000 host lab106-ssd
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
-28 4.00000 host lab105-sata
18 2.00000 osd.18 up 1.00000 0
19 2.00000 osd.19 up 1.00000 0
-50 8.00000 chassis chassis-lab107-ssd-3
-22 4.00000 host lab107-ssd
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
-29 4.00000 host lab106-sata
22 2.00000 osd.22 up 1.00000 0
23 2.00000 osd.23 up 1.00000 0
-51 8.00000 chassis chassis-lab108-ssd-3
-23 4.00000 host lab108-ssd
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
-30 4.00000 host lab107-sata
26 2.00000 osd.26 up 1.00000 0
27 2.00000 osd.27 up 1.00000 0
|
tree的内容比较多,还是用个图来说明
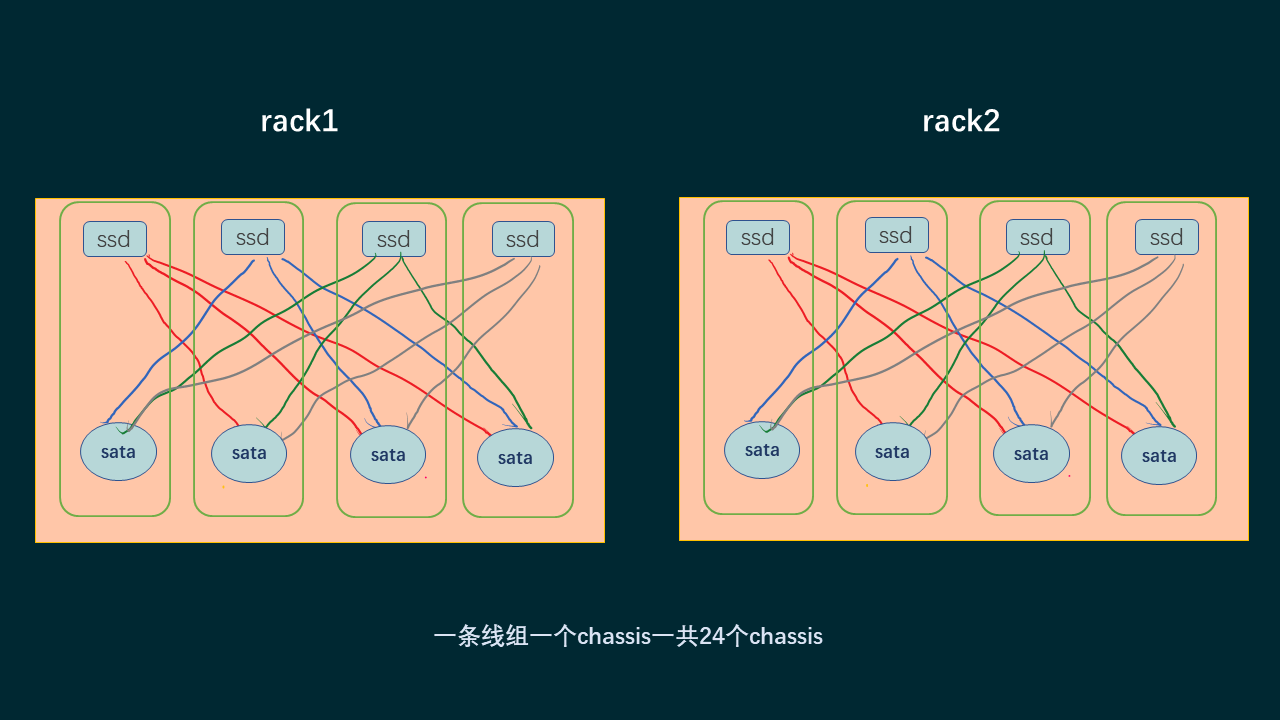
pg的分布是这样的
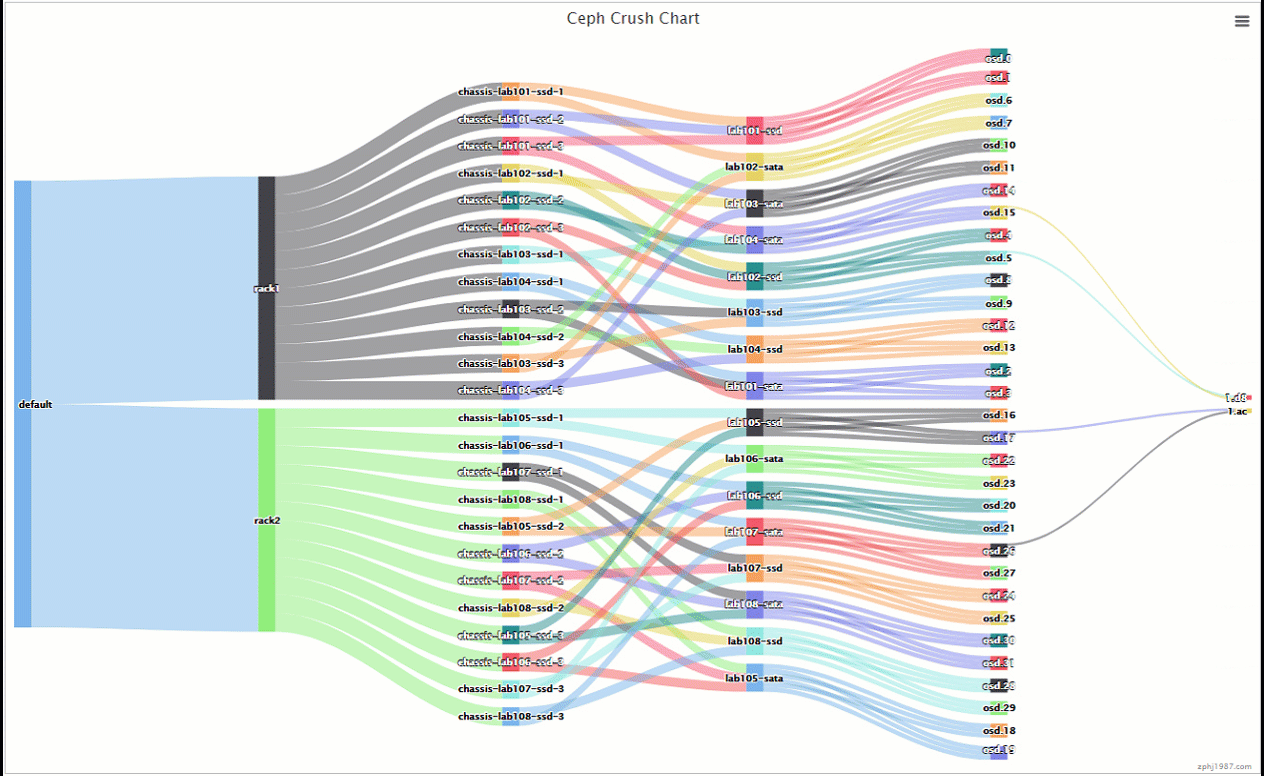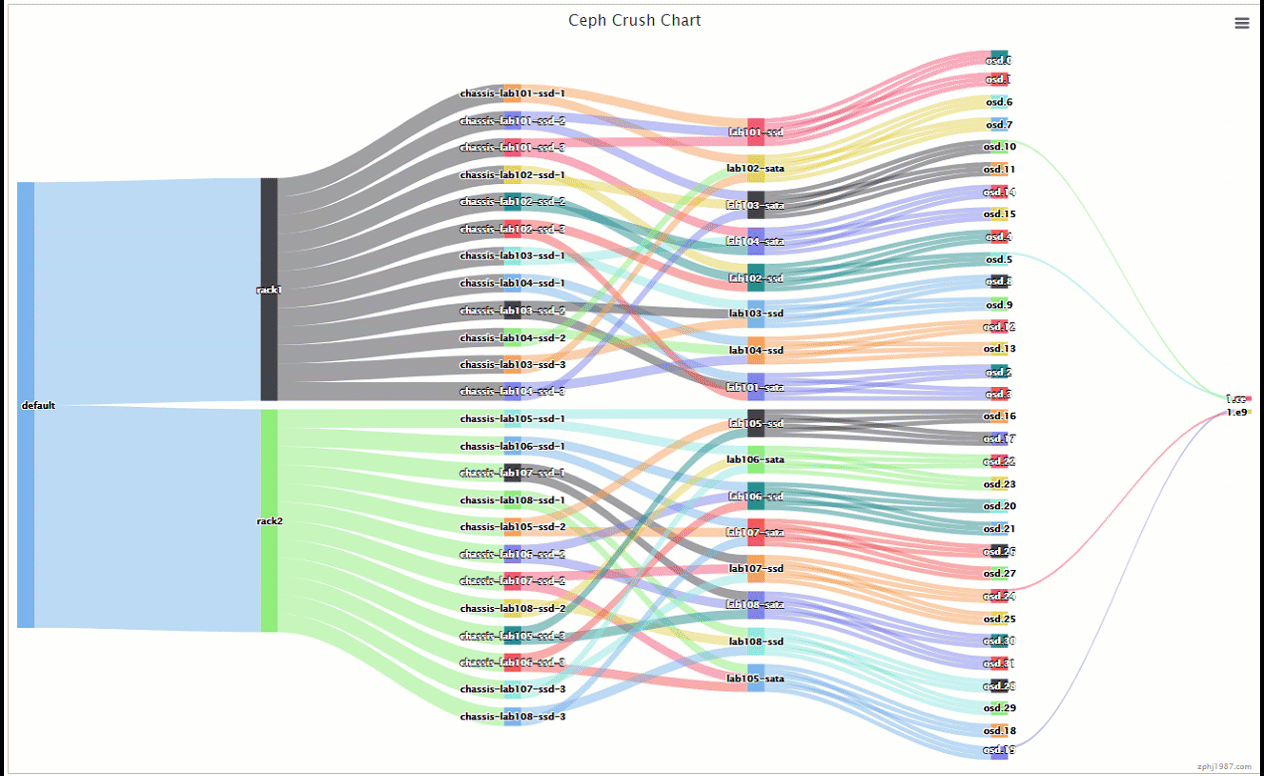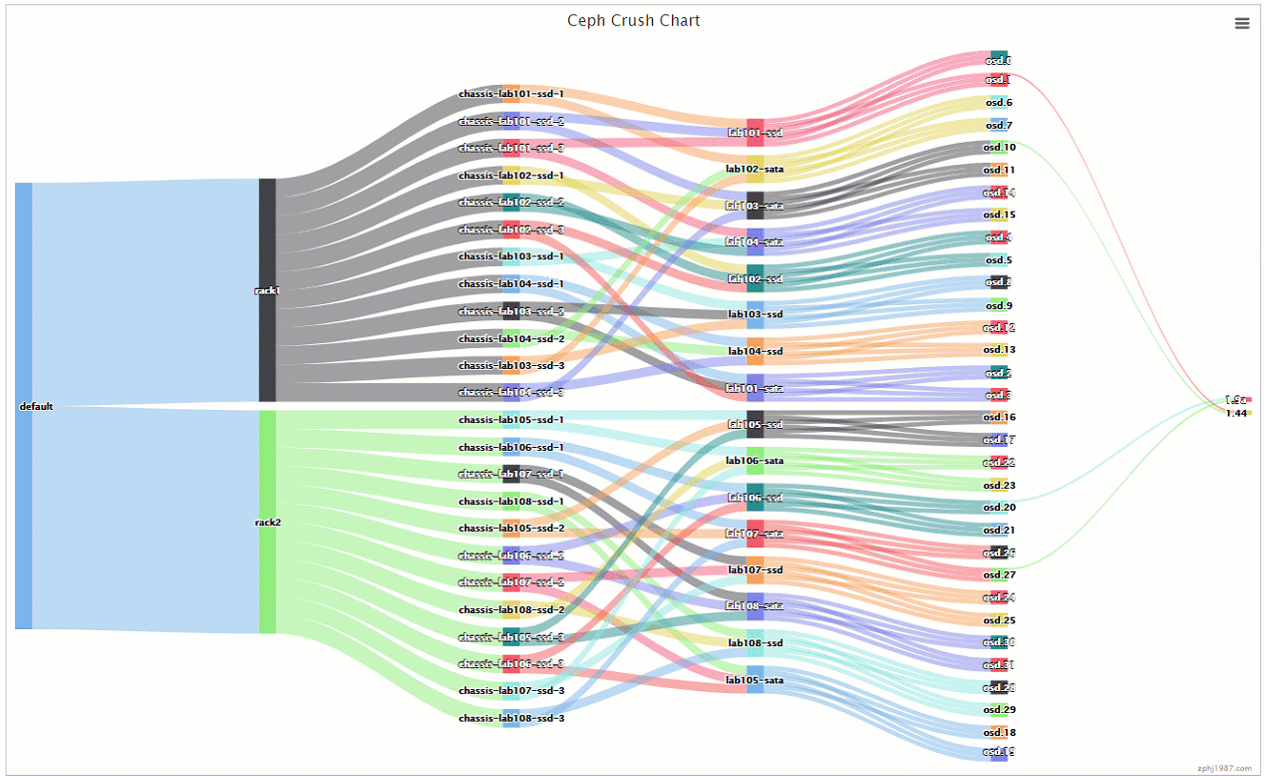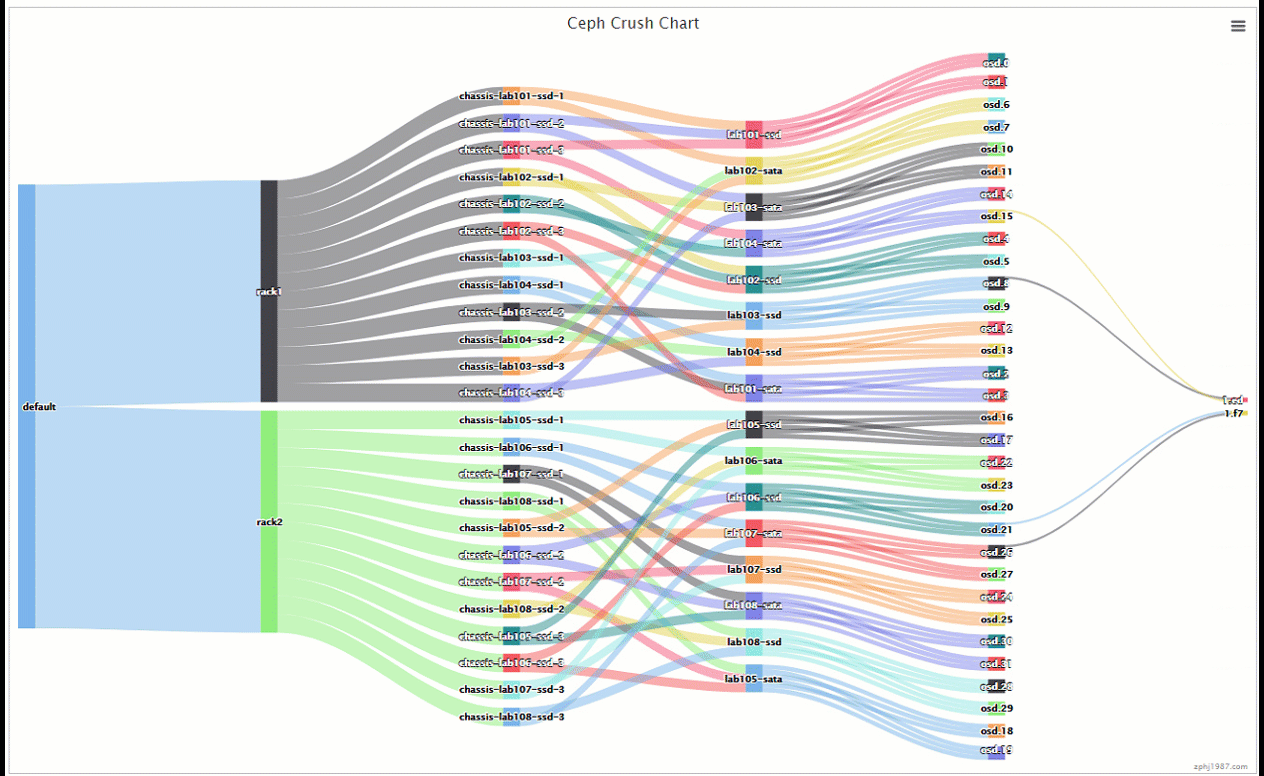
可以看到pg是分布在一个ssd上一个sata上,并且分布上面,比上面的那种交叉更多了的
模式五:写本地
上面的控制是控制写入到ssd里面,在选择ssd的时候,就让他随机的进行选择的,那么有的时候,我们的环境不大,我只需要尽量写本机,读本地,同时能够有一个副本能够去保证我们的可用性的时候,那么就可以控制一个写入在本地的情况,在一些存储软件里面都有一个设计是local read的设计,如果需要的对象在本地,那么就直接通过程序去从本地的host 本地进行读取即可,这个在ceph里面某些接口里面已经做了,之前有篇文章也写到过,本篇跟那篇是有区别的,这里的设计是通过控制把数据完全写到本地机器去的
我们来看看怎么弄
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| [root@lab101 ~]
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 112.00000 root default
-12 16.00000 host lab101
0 2.00000 osd.0 up 1.00000 1.00000
1 2.00000 osd.1 up 1.00000 1.00000
2 2.00000 osd.2 up 1.00000 1.00000
3 2.00000 osd.3 up 1.00000 1.00000
4 2.00000 osd.4 up 1.00000 1.00000
5 2.00000 osd.5 up 1.00000 1.00000
6 2.00000 osd.6 up 1.00000 1.00000
7 2.00000 osd.7 up 1.00000 1.00000
-13 16.00000 host lab102
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
10 2.00000 osd.10 up 1.00000 1.00000
11 2.00000 osd.11 up 1.00000 1.00000
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
14 2.00000 osd.14 up 1.00000 1.00000
15 2.00000 osd.15 up 1.00000 1.00000
-14 16.00000 host lab103
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
18 2.00000 osd.18 up 1.00000 1.00000
19 2.00000 osd.19 up 1.00000 1.00000
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
22 2.00000 osd.22 up 1.00000 1.00000
23 2.00000 osd.23 up 1.00000 1.00000
-15 16.00000 host lab104
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
26 2.00000 osd.26 up 1.00000 1.00000
27 2.00000 osd.27 up 1.00000 1.00000
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
30 2.00000 osd.30 up 1.00000 1.00000
31 2.00000 osd.31 up 1.00000 1.00000
-2 48.00000 chassis chassis-for-lab101
-13 16.00000 host lab102
8 2.00000 osd.8 up 1.00000 1.00000
9 2.00000 osd.9 up 1.00000 1.00000
10 2.00000 osd.10 up 1.00000 1.00000
11 2.00000 osd.11 up 1.00000 1.00000
12 2.00000 osd.12 up 1.00000 1.00000
13 2.00000 osd.13 up 1.00000 1.00000
14 2.00000 osd.14 up 1.00000 1.00000
15 2.00000 osd.15 up 1.00000 1.00000
-14 16.00000 host lab103
16 2.00000 osd.16 up 1.00000 1.00000
17 2.00000 osd.17 up 1.00000 1.00000
18 2.00000 osd.18 up 1.00000 1.00000
19 2.00000 osd.19 up 1.00000 1.00000
20 2.00000 osd.20 up 1.00000 1.00000
21 2.00000 osd.21 up 1.00000 1.00000
22 2.00000 osd.22 up 1.00000 1.00000
23 2.00000 osd.23 up 1.00000 1.00000
-15 16.00000 host lab104
24 2.00000 osd.24 up 1.00000 1.00000
25 2.00000 osd.25 up 1.00000 1.00000
26 2.00000 osd.26 up 1.00000 1.00000
27 2.00000 osd.27 up 1.00000 1.00000
28 2.00000 osd.28 up 1.00000 1.00000
29 2.00000 osd.29 up 1.00000 1.00000
30 2.00000 osd.30 up 1.00000 1.00000
31 2.00000 osd.31 up 1.00000 1.00000
|
tree是这样的,主机的是默认的,在里面增加一个chassis来装除了lab101以外的机器,这样等下在选择的时候,先从lab101里面抽一个osd出来,然后再从剩余的chassis里面抽个主机里面的osd出来就行了
看下做的rule
1
2
3
4
5
6
7
8
9
10
11
12
13
| }
rule for-lab101 {
ruleset 2
type replicated
min_size 1
max_size 10
step take lab101
step chooseleaf firstn 1 type osd
step emit
step take chassis-for-lab101
step chooseleaf firstn 1 type host
step emit
}
|
检查下pg的状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| [root@lab101 ~]
dumped pgs in format plain
pg_stat up_primary
1.ff [5,21]
1.fe [6,14]
1.fd [5,18]
1.fc [6,28]
1.fb [7,30]
1.fa [0,31]
1.f9 [7,21]
1.f8 [7,14]
1.f7 [6,13]
1.f6 [5,16]
1.f5 [7,10]
1.f4 [3,31]
1.f3 [4,29]
1.f2 [4,15]
|
可以看到主本都在第一个主机的osd上面,如果每个主机都想这样,那就做不同的rule,做不同的存储池就可以了
总结
ceph里面的crush比较复杂的一些玩法在本篇中基本都有提及,一般来说,只要你想得到的分布,ceph都是能够去做到的,这个得益于灵活的crush控制,这个也是ceph优于一些其他分布式软件的一点,软件的控制很多,关键是找到适合自己用的,复杂度高的crush意味着后期的维护的时候操作上需要更细粒度的控制,而把这些做到ui层面去,又增加了软件的难度,所以什么是交给客户的什么是专业技术去控制的,这个需要划分好
自己写的工具自己多用用才能更好的发现问题,比如上面的crush分布的,本篇文章用的过程中就发现了osd的排序问题,以及加入了可以指定随机的pg个数的功能
变更记录
| Why |
Who |
When |
| 创建 |
武汉-运维-磨渣 |
2019-3-22 |