osd磁盘空间足够无法写入数据的分析与解决
前言
这个问题的来源是ceph社区里面一个群友的环境出现在85%左右的时候,启动osd报错,然后在本地文件系统当中进行touch文件的时候也是报错,df -i查询inode也是没用多少,使用的也是inode64挂载的,开始的时候排除了配置原因引起的,在ceph的邮件列表里面有一个相同问题,也是没有得到解决
看到这个问题比较感兴趣,就花了点时间来解决来定位和解决这个问题,现在分享出来,如果有类似的生产环境,可以提前做好检查预防工作
##现象描述
ceph版本
[root@lab8107 mnt]# ceph -v
ceph version 10.2.9 (2ee413f77150c0f375ff6f10edd6c8f9c7d060d0)
我复现的环境为这个版本
查询使用空间
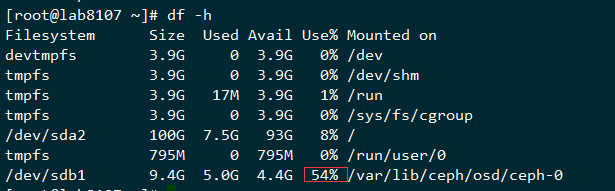
可以看到空间才使用了54%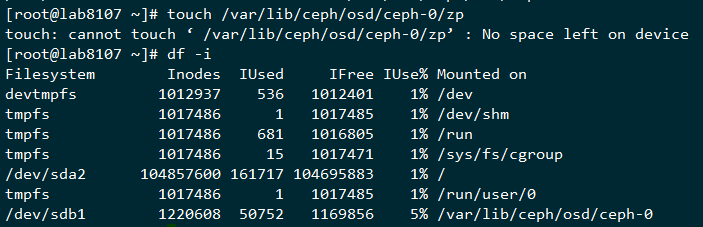
可以看到,inode剩余比例很多,而文件确实无法创建
这个时候把一个文件mv出来,然后又可以创建了,并且可以写入比mv出来的文件更大的文件,写完一个无法再写入更多文件了
这里有个初步判断,不是容量写完了,而是文件的个数限制住了
那么来查询下文件系统的inode还剩余多少,xfs文件系统的inode是动态分配的,我们先检查无法写入的文件系统的
1 | |

可以看到剩余的inode确实为0,这里确实是没有剩余inode了,所以通过df -i来判断inode是否用完并不准确,那个是已经使用值与理论值的相除的结果
查询xfs碎片,也是比例很低
定位问题
首先查看xfs上面的数据结构
1 | |
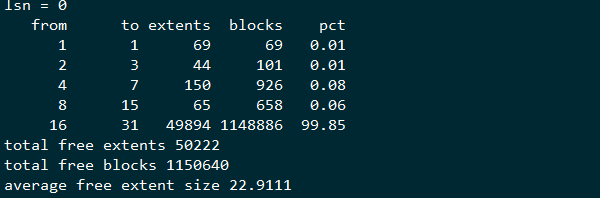
上面的输出结果这里简单解释一下,这里我也是反复比对和查看资料才理解这里的意思,这里有篇novell的资料有提到这个,这里我再拿一个刚刚格式化完的分区结果来看下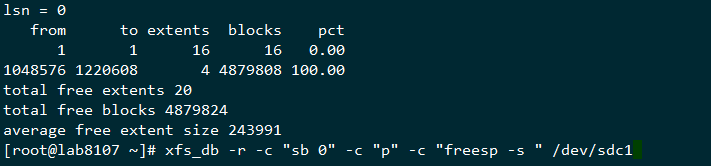
这里用我自己的理解来描述下,这个extents的剩余数目是动态变化的,刚分完区的那个,有4个1048576-1220608左右的逻辑区间,而上面的无法写入数据的数据结构,剩下的extent的平均大小为22个block,而这样的blocks总数有1138886个,占总体的99.85,也就是剩余的空间的的extents所覆盖的区域全部是16个block到31个block的这种空洞,相当于蛋糕被切成很多小块了,大的都拿走了,剩下的总量还很多,但是都是很小的碎蛋糕,所以也没法取了
默认来说inode chunk 为64 ,也就是需要64*inodesize的存储空间来存储inode,这个剩下的空间已经不够分配了
解决办法
下个段落会讲下为什么会出现上面的情况,现在先说解决办法,把文件mv出来,然后mv进去,这个是在其他场景下的一个解决方法,这个操作要小心,因为有扩展属性,操作不小心会弄掉了,这里建议用另外一个办法xfs_dump的方法
我的环境比较小,20G的盘,如果盘大就准备大盘,这里是验证是否可行
1 | |
还原回去
1 | |
直接还原还是会有问题,没有可以写的地方了,这里因为已经dump了一份,这里就mv pg的数据目录出去
1 | |
开始还原
1 | |
还原以后如果有权限需要处理的就处理下权限,先检查下文件系统的数据结构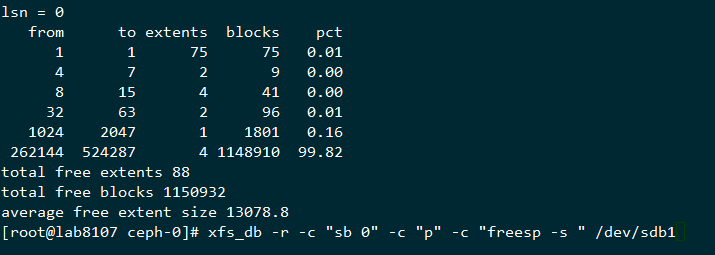
可以看到数据结构已经很理想了
然后启动osd
1 | |
然后检查下数据是不是都可以正常写进去了
- 如果出现了上面的空间已经满了的情况,处理的时候需要注意
- 备份好数据
- 单个盘进行处理
- 备份的数据先保留好以防万一
- 启动好了后,验证下集群的状态后再继续,可以尝试get下数据检查数据
为什么会出现这样
我们在本地文件系统里面连续写100个文件
准备一个a文件里面有每行150个a字符,700行,这个文件大小就是100K
1 | |
检查文件的分布
1 | |
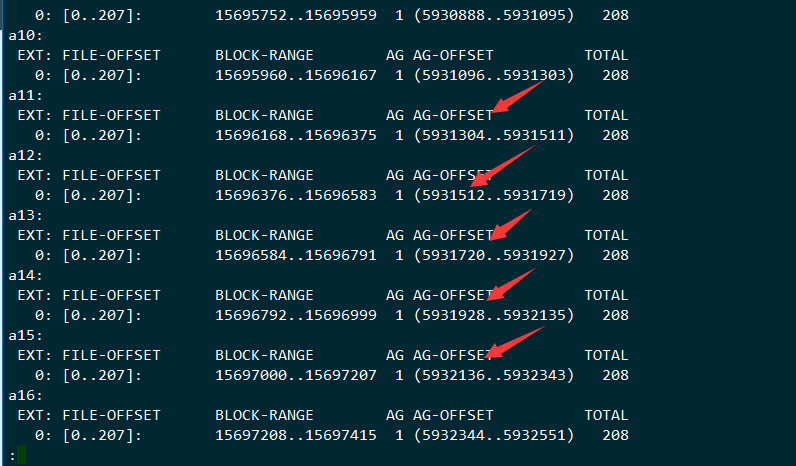
大部分情况下这个block的分配是连续的
先检查下当前的数据结构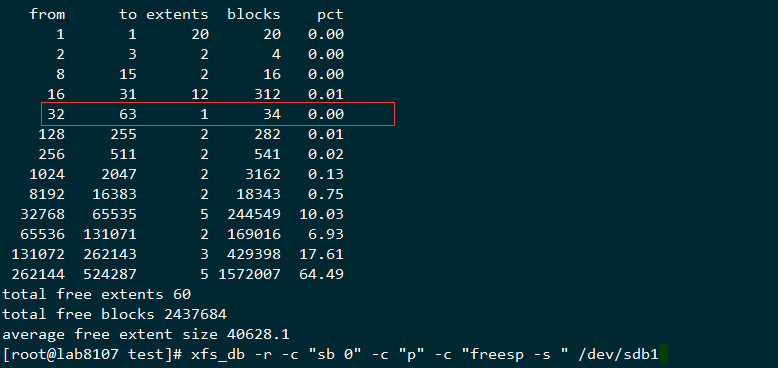
我们把刚刚的100个对象put到集群里面去,监控下集群的数据目录的写入情况
1 | |
put数据进去
1 | |
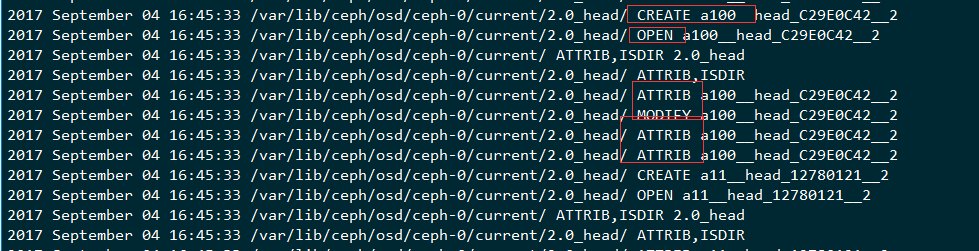
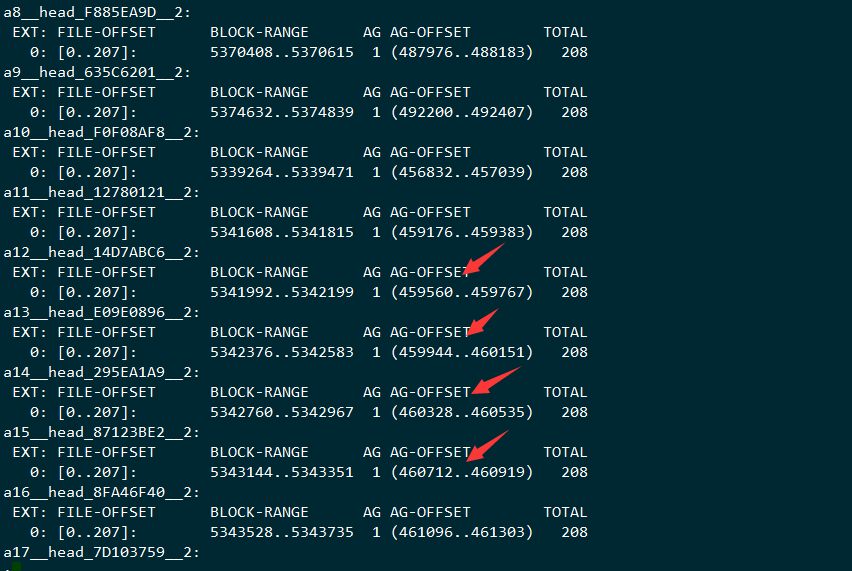
查看对象的数据,里面并没有连续起来,并且写入的数据的方式是:
打开文件,设置扩展属性,填充内容,设置属性,关闭,很多并发在一起做
写完的数据结构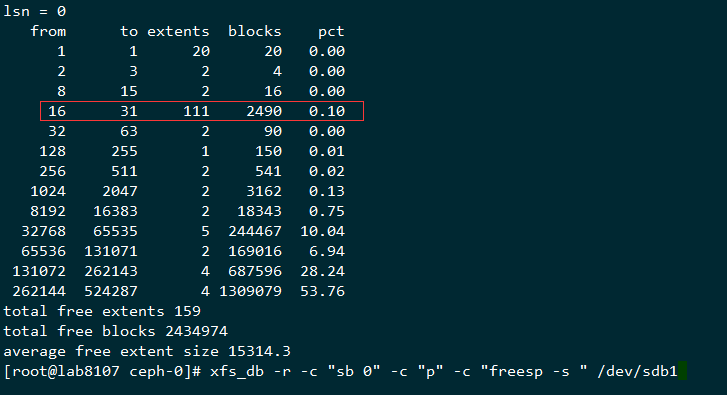
结果就是在100K这个数据模型下,会产生很多小的block空隙,最后就是无法写完文件的情况,这里产生空隙并不是很大的问题,问题是这里剩下的空隙无法完成inode的动态分配的工作,这里跟一个格式化选项的变化有关
准备一个集群
然后写入(一直写)
1 | |
就可以必现这个问题,可以看到上面的从16-31 block的区间从 12 extents涨到了111 extents
解决办法
用deploy在部署的时候默认的格式化参数为
1 | |
这个isize设置的是2048,这个在后面剩余的空洞比较小的时候就无法写入新的数据了,所以在ceph里面存储100K这种小文件的场景的时候,把mkfs.xfs的isize改成默认的256就可以提前避免这个问题
修改 /usr/lib/python2.7/site-packages/ceph_disk/main.py的256行
1 | |
改成
1 | |
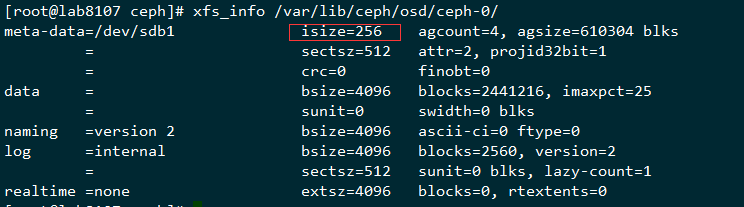
这个地方检查下是不是对的,然后就可以避免这个问题了,可以测试下是不是一直可以写到很多,我的这个测试环境写到91%还没问题
总结
在特定的数据写入模型下,可能出现一些可能无法预料的问题,而参数的改变可能也没法覆盖所有场景,本篇就是其中的一个比较特殊的问题,定位好问题,在遇到的时候能够解决,或者提前避免掉
后续
在升级了内核到
1 | |
升级xfsprogs到
1 | |
重新部署osd,还是一样的isize=2048,一样的写入模型
1 | |
1 | |
可以看到已经很少的稀疏空间了,留下比较大的空间,这个地方应该是优化了底层数据存储的算法
另外,xfs的inode是动态分配的,xfs官方也考虑到了这个可能空洞太多无法分配inode问题,这个是最新的mkfs.xfs的man page
1 | |
是以64个inode为chunk来进行动态分配的,应该是有两个chunk,也就是动态查询看到的是128个inode以下,在更新到最新的版本以后,因为已经没有那么多空洞了,所以即使在没开这个稀疏inode的情况下,ceph的小文件也能够把磁盘写满
变更记录
| Why | Who | When |
|---|---|---|
| 创建 | 武汉-运维-磨渣 | 2017-09-04 |
| 增加更新内核和xfsprogs的验证 | 武汉-运维-磨渣 | 2017-09-05 |