ceph 的crush算法 straw
很多年以前,Sage 在写CRUSH的原始算法的时候,写了不同的Bucket类型,可以选择不同的伪随机选择算法,大部分的模型是基于RJ Honicky写的RUSH algorithms 这个算法,这个在网上可以找到资料,这里面有一个新的特性是sage很引以为豪的,straw算法,也就是我们现在常用的一些算法,这个算法有下面的特性:
- items 可以有任意的weight
- 选择一个项目的算法复杂度是O(n)
- 如果一个item的weight调高或者调低,只会在调整了的item直接变动,而没有调整的item是不会变动的
O(n)找到一个数组里面最大的一个数,你要把n个变量都扫描一遍,操作次数为n,那么算法复杂度是O(n)
冒泡法的算法复杂度是O(n²)
这个过程的算法基本动机看起来像画画的颜料吸管,最长的一个将会获胜,每个item 基于weight有自己的随机straw长度
这些看上去都很好,但是第三个属性实际上是不成立的,这个straw 长度是基于bucket中的其他的weights来进行的一个复杂的算法的,虽然iteam的PG的计算方法是很独立的,但是一个iteam的权重变化实际上影响了其他的iteam的比例因子,这意味着一个iteam的变化可能会影响其他的iteam
这个看起来是显而易见的,但是事实上证明,8年都没有人去仔细研究底层的代码或者算法,这个影响就是用户做了一个很小的权重变化,但是看到了一个很大的数据变动过程,sage 在做的时候写过一个很好的测试,来验证了第三个属性是真的,但是当时的测试只用了几个比较少的组合,如果大量测试是会发现这个问题的
sage注意到这个问题也是很多人抱怨在迁移的数据超过了预期的数据,但是这个很难量化和验证,所以被忽视了很久
无论如何,这是个坏消息
好消息是,sage找到了如何解决分布算法来的实现这三个属性,新的算法被称为 ‘straw2’,下面是不同的算法
straw的算法
1 | |
这个就有问题了scaling factor(比例因子) 是其他iteam的权重所有的,这个就意味着改变A的权重,可能会影响到B和C的权重了
新的straw2的算法是这样的
1 | |
可以看到这个是一个weight的简单的函数,这个意味着改变一个item的权重不会影响到其他的项目
sage发现问题的一半,然后 sam根据这个算法解决了问题
计算ln()函数有点讨厌,因为这个是一个浮点功能,CRUSH是定点运算(整数型),当前的实施方法是128KB的查找表,在做一个小的单元测试的时候比straw慢了25%,单这个可能跟一些缓存和输入也有关系
以上是2014年sage在开发者邮件列表里面提出来的,相信到现在为止straw2的算法已经改进了很多,目前默认的还是straw算法,内核在kernel4.1以后才支持的这个属性的
那么我们在0.9x中来看下这个属性,来从实际环境中看下具体有什么区别
实践过程
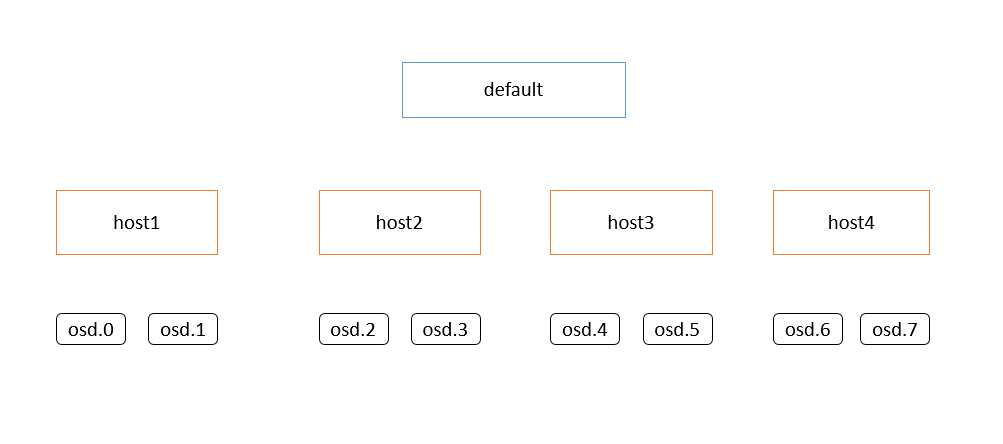
基础的环境为这个,我的机器为8个osd的单机节点,通过修改crush模拟成如上图所示的环境,设置的pg数目为800,保证每个osd上的pg为100左右,这个增加pg的数目,来扩大测试的样本
straw2和straw的区别在于,straw算法改变一个bucket的权重的时候,因为内部算法的问题,造成了其他机器的item的计算因子也会变化,就会出现其他没修改权重的bucket也会出现pg的相互间的流动,这个跟设计之初的想法是不一致的,造成的后果就是,在增加或者减少存储节点的时候,如果集群比较大,数据比较多,就会造成很大的无关数据的迁移,这个就是上面提到的问题
为了解决这个问题就新加入了算法straw2,这个算法保证在bucket的crush权重发生变化的时候,只会在变化的bucket有数据流入或者流出,不会出现其他bucket间的数据流动,减少数据的迁移量,下面的测试将会直观的看到这种变化
环境配置
调整tunables 为 hammer,这个里面才支持crush v4(straw2)属性
1 | |
设置完了检查这两个个属性,如果是straw_calc_version 0的时候profile会显示unknow
1 | |
设置完了后并不能马上生效的,这个是为了防止集群大的变动,可以用这个触发,或者等待下次crush发生变动的时候会自动触发
1 | |
##先来测试straw
开始第一步测试,将osd.7从集群中crush改为0,那么变动的就是host4的crush,那么我们来看下数据的变化
首先需要记录原始的pg分布
1 | |
现在比较oringin 和rewei70 的变化
1 | |
查看非调整节点的数据流动
1 | |
再来一次将osd.6的crush weight弄成0
1 | |
再次查看变化
1 | |
上面的两组就是在一个bucket的里面的出现单点和整个bucket的crush weight减少的时候触发的其他节点的数据变动
现在把环境恢复后再来测试straw2
修改crush map 里面的bucket的alg
1 | |
如果出现报错就把crushmap里面的straw2_calc_version改成straw_calc_version
并且设置算法(最关键的一步,否则即使设置straw2也不生效)(这里之前版本有version 2 现在已经没那个字段了)
1 | |
查询当前的crush算法
1 | |
做一次重新内部算法
1 | |
可以重复上面的测试了
获取当前的pg分布
1 | |
比较调整前后
1 | |
再次调整osd.6
1 | |
已经没有非调整bucket的pg在节点间的变化了
简短的做个总结就是
straw算法里面添加节点或者减少节点,其他服务器上的osd之间会有pg的流动
straw2算法里面添加节点或者减少节点,只会pg从变化的节点移出或者从其他点移入,其他节点间没有数据流动
设置方法
1 | |
开始设置好了 新创建的默认就是会straw2就会省去修改crushmap的操作
注意librados是服务端支持,客户端就支持,涉及到内核客户端的,就需要内核版本的支持,内核从4.1开始支持,也就是cephfs和rbd的块设备方式需要内核4.1及以上支持,openstack对接的是librados可以默认支持,其他的也都默认可以支持的