Ceph中的Copyset概念和使用方法
前言
copyset运用好能带来什么好处
- 降低故障情况下的数据丢失概率(增加可用性)
- 降低资源占用,从而降低负载
copyset的概念
首先我们要理解copyset的概念,用通俗的话说就是,包含一个数据的所有副本的节点,也就是一个copyset损坏的情况下,数据就是全丢的
如上图所示,这里的copyset就是:
{1,5,6},{2,6,8} 两组
如果不做特殊的设置,那么基本上就是会随机的去分布
最大copyset
如上图的所示,一般来说,最终组合将是一个最大的随机组合,比如这样的一个9个node随机组合3个的,这样的组合数有:
从 n个元素中取出 k个元素, k个元素的组合数量为: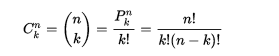
9个随机3个的组合为84
如果3个节点down掉,那么有数据丢失概率就是100%
最小copyset
如果存在一种情况,分布是这样的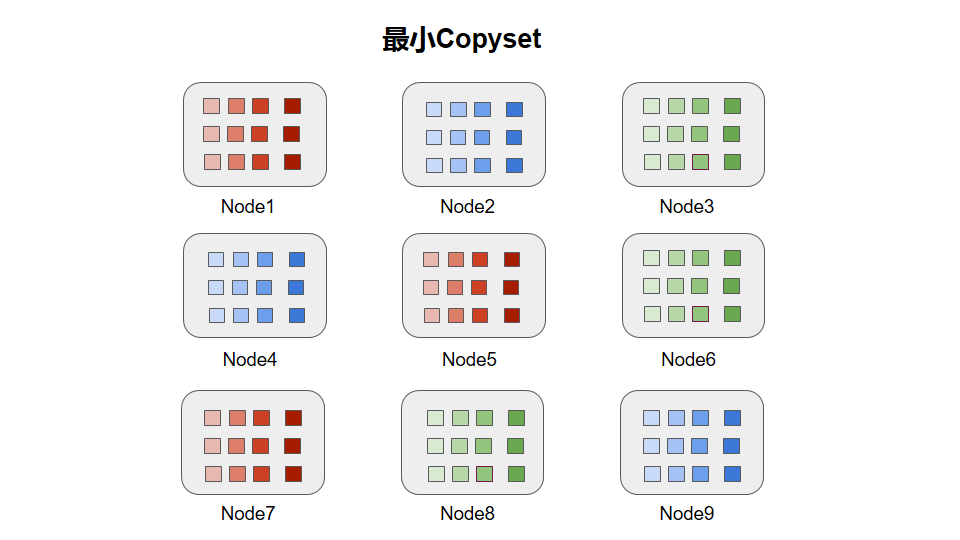
那么copyset为
{1,5,7},{2,4,9},{3,6,8}
如果3个节点down掉,只有正好是上面的3种组合中的一种出现的时候,才会出现数据丢失
那么数据丢失的概率为 3/84
最小copyset可能带来的不好的地方
- 真出现丢失的时候(概率极低),丢失的数据量将是最大化的,这个是因为出现丢的时候,那么三个上面的组合配对为100%,其他情况不是100%
- 失效恢复时间将会增大一些,根据facebook的报告100GB的39节点的HDFS随机分布恢复时间在60s,最小分布为700s,这个是因为可用于恢复的点相对减少了,恢复时间自然长了
比较好的处理方式
比较好的方式就是取copyset值为介于纯随机和最小之间的数,那么失效的概率计算方式就是:
当前的copyset数目/最大copyset
这个概念在ceph当中的实现
其实这个概念在ceph当中就是bucket的概念,PG为最小故障单元,PG就可以理解为上图当中的node上的元素,默认的分组方式为host,这个copyset就是全随机的在这些主机当中进行组合,我们在提升故障域为rack的时候,实际上就是将copyset进行了减少,一个rack之内的主机是形成不了copyset,这样down掉rack的时候,就不会数据丢失了,这个地方的实际可以做的控制方式有三种,下面将详细的介绍三种模式
缩小最小主机单位
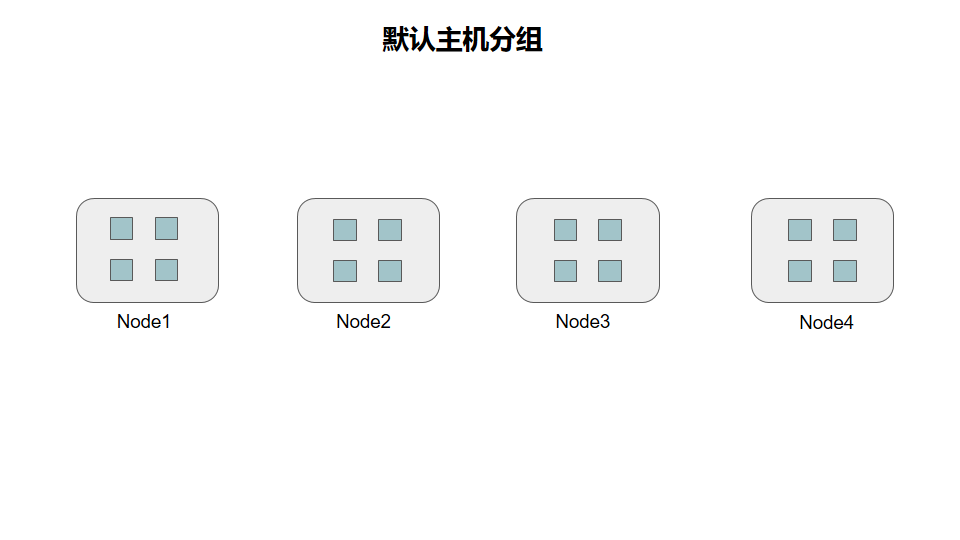
默认的为主机组,这样的主机间的copyset为
{1,2},{1,3},{1,4},{2,3},{2,4},{3,4}
这样的有六组
现在我们对host进行一个合并看下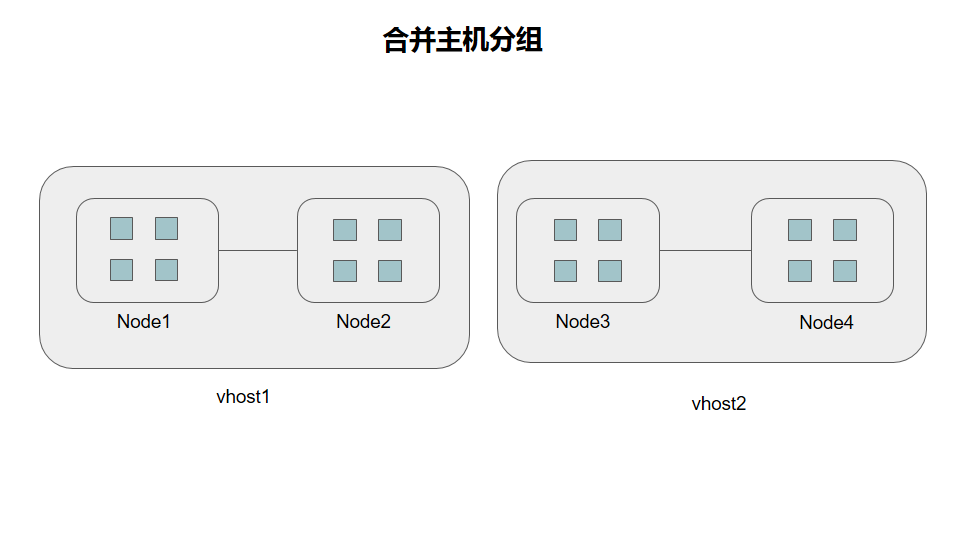
注意这个地方并不是往上加了一层bucket,而是把最底层的host给拆掉了,加入一台机器有24个osd,那么这里的vhost1里面的osd个数实际是48个osd,那么当前的copyset为
{vhost1,vhost2}
copyset已经为上面默认情况的1/6
这样会带来两个好处
- 减少了copyset,减少的好处就见上面的分析
- 增加可接收恢复的osd数目,之前坏了一个osd的时候,能接收数据的osd为n-1,那么现在坏一个osd,可接收的osd为2n-1(n为单node上的osd个数)
增加分组
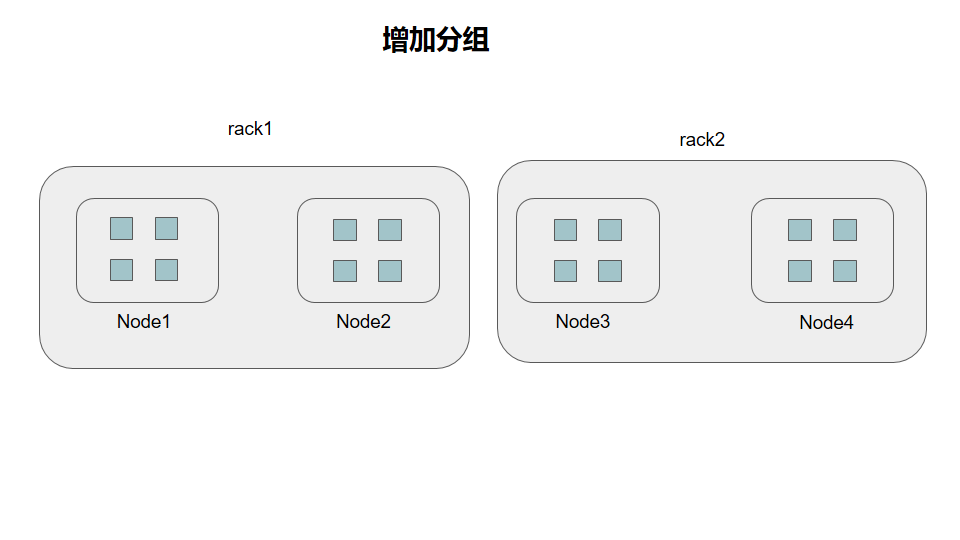
这个地方是增加了rack分组的,同一个rack里面不会出现copyset,那么当前的模式的copyset就是
{1,3},{1,4},{2,3},{2,4}
同没有处理相比copyset为4/6
增加分组的情况进行PG分流
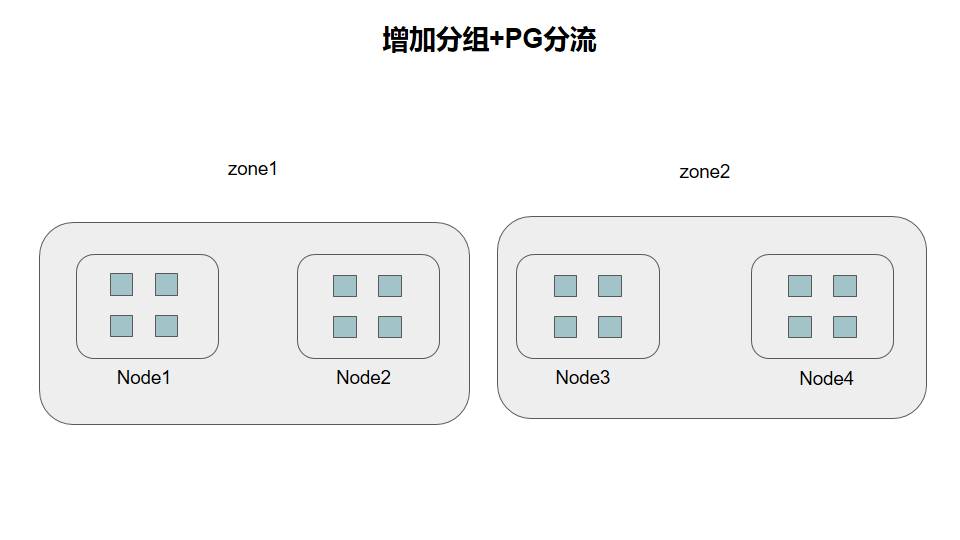
这里看上去跟上面的分组很像,但是在做crush的时候是有区别的,上面的分组以后,会让PG分布在两个rack当中,这里的crush写的时候会让PG只在一个zone当中,在进入zone的下层再去进行分离主副PG,那么这种方式的copyset为
{1,2} {3,4}
为上面默认情况的2/6
总结
关于ceph中的ceph的copyset的三种模式已经总结完了,需要补充的是,上面的node都是一个虚拟的概念,你可以扩充为row,或者rack都行,这里只是说明了不同的处理方式,针对每个集群都可以有很多种组合,这个关键看自己怎么处理,减少copyset会明显的减低机器上的线程数目和资源的占用,这一点可以自行研制,从原理上来说少了很多配对的通信,crush的是非常灵活的一个分布控制,可以做很精细的控制,当然也会增加了维护的难度
参考资料:
打造高性能高可靠块存储系统
Copysets: Reducing the Frequency of Data Loss in Cloud Storage
变更记录
| Why | Who | When |
|---|---|---|
| 创建 | 武汉-运维-磨渣 | 2016-09-06 |