Ceph Bluestore首测
Bluestore 作为 Ceph Jewel 版本推出的一个重大的更新,提供了一种之前没有的存储形式,一直以来ceph的存储方式一直是以filestore的方式存储的,也就是对象是以文件方式存储在osd的磁盘上的,pg是以目录的方式存在于osd的磁盘上的
在发展过程中,中间出现了kvstore,这个还是存储在文件系统之上,以leveldb或者rocksdb的方式存储对象数据,这个也没有推广开来,性能上没有太大的改观,在某些情况下性能还低于filestore
最终在sage的大力支持下,ceph社区准备撸一个新的文件系统,这个系统类似于rocksdb,但是数据是可以直接存储到裸设备上去的,也就是存储对象数据的地方是没有传统意义上的文件系统的,并且解决了一种被抱怨的写双份数据的问题,在filestore中,数据需要先写入journal再入磁盘,对于磁盘来说实际就是双份写了
在这里不做过多的探讨技术上的细节,bluestore处于开发阶段,在最新的版本的ceph中,发现已经集成了这个,虽然还是实验阶段,但是还是体现出其未来巨大的价值
环境准备
由于没有测试大量的设备,就在一个小环境下进行性能的验证,基准的性能不需要大量的机器,至于数据可靠性,就靠自己去判断了
硬件环境:

软件环境:

一、先测试Filestore
ceph-disk有个update_partition的bug,部署过程需要处理一下,后期发版本应该会解决
1、4K随机写200G的rbd测试时间300s
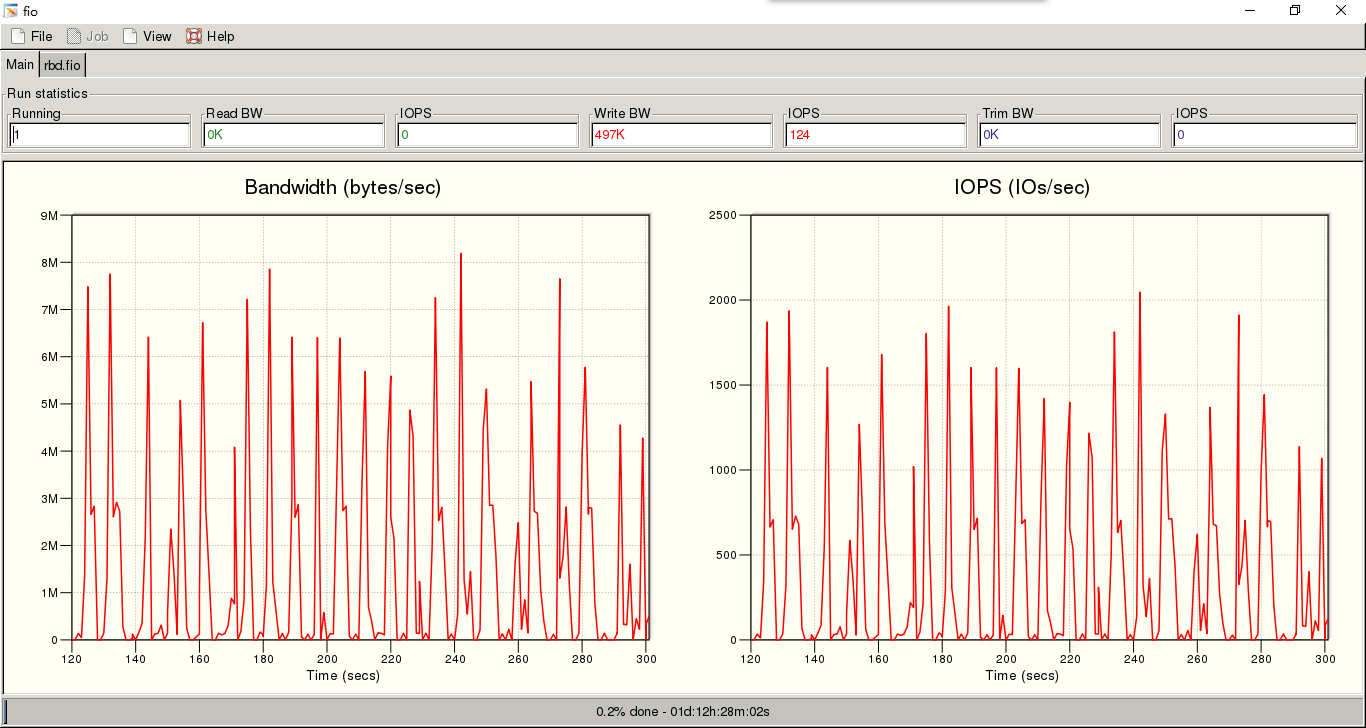
测试的io的抖动的情况
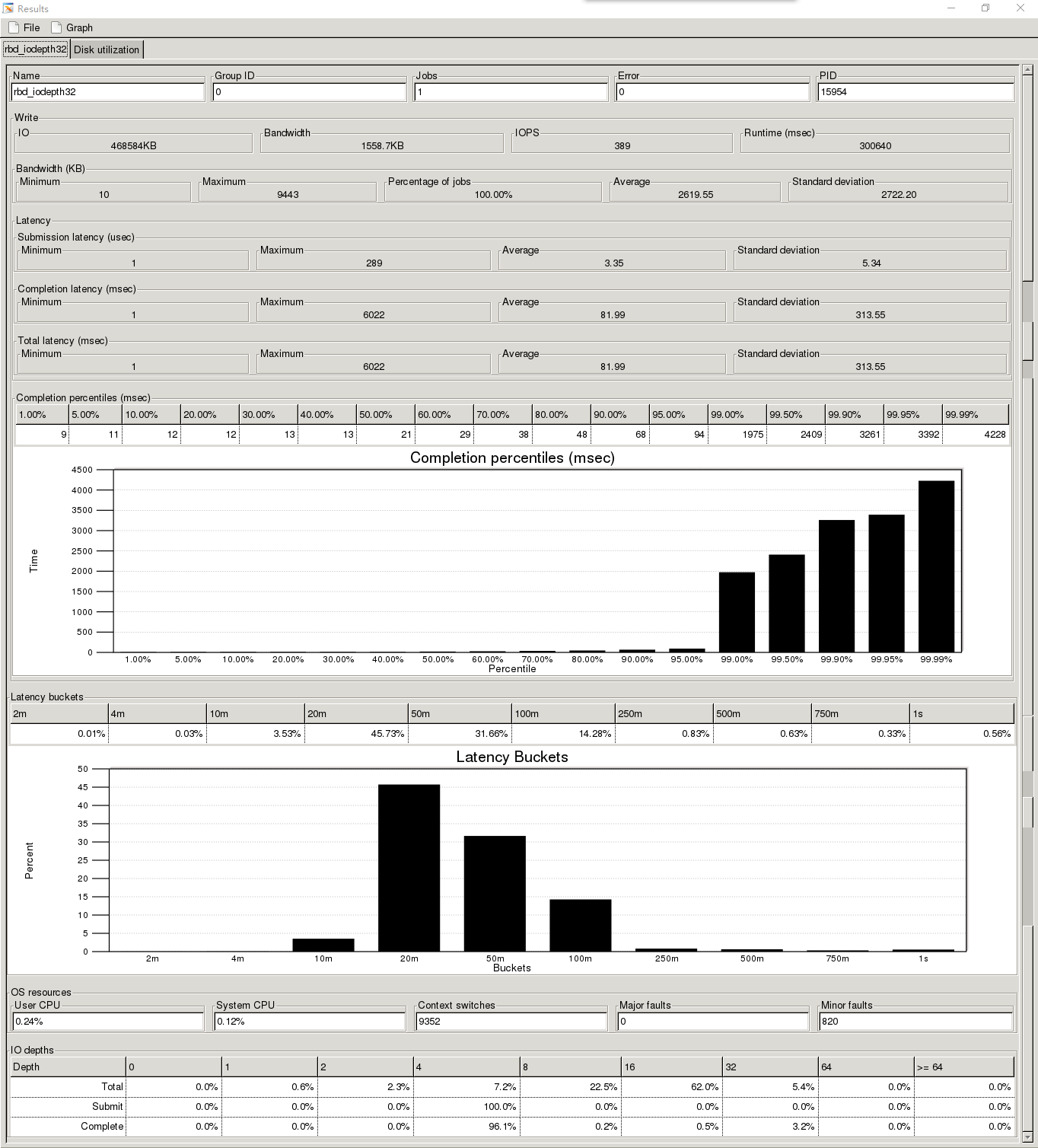
测试的FIO结果的页面
2、4M顺序写200G的rbd测试时间300s
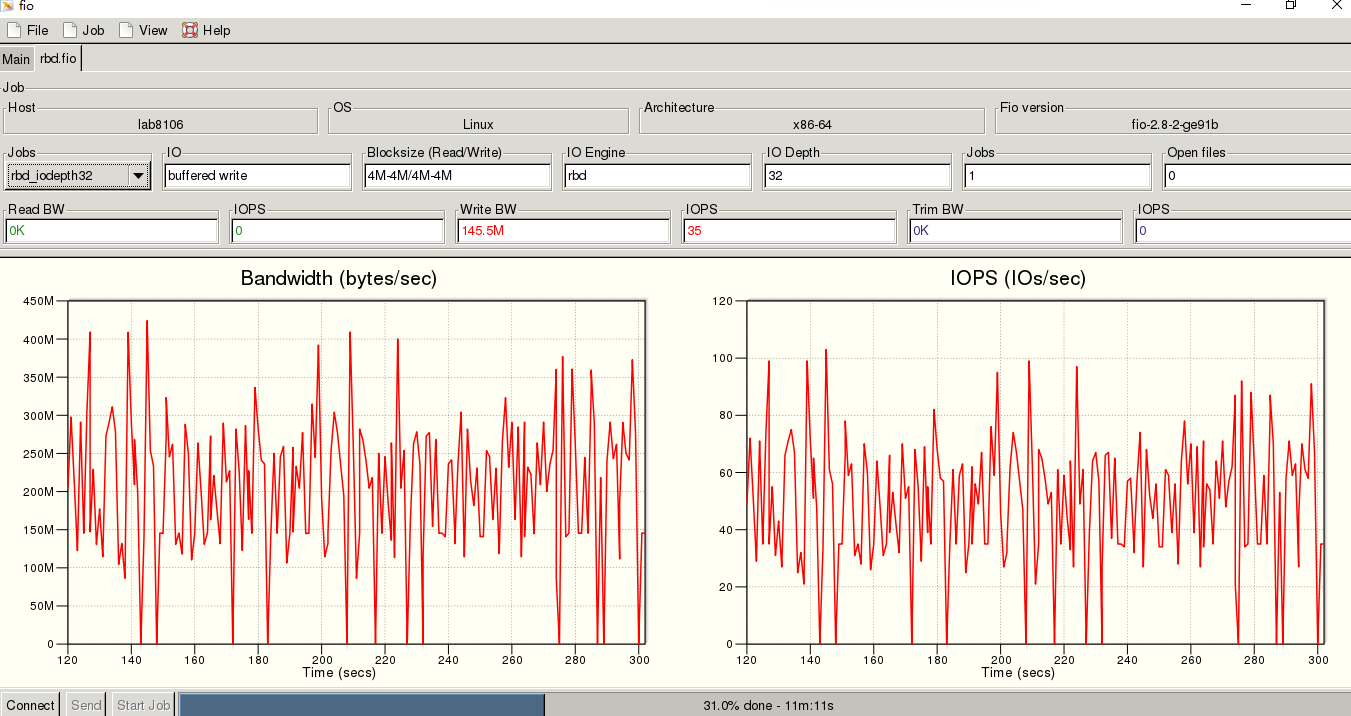
测试的io的抖动的情况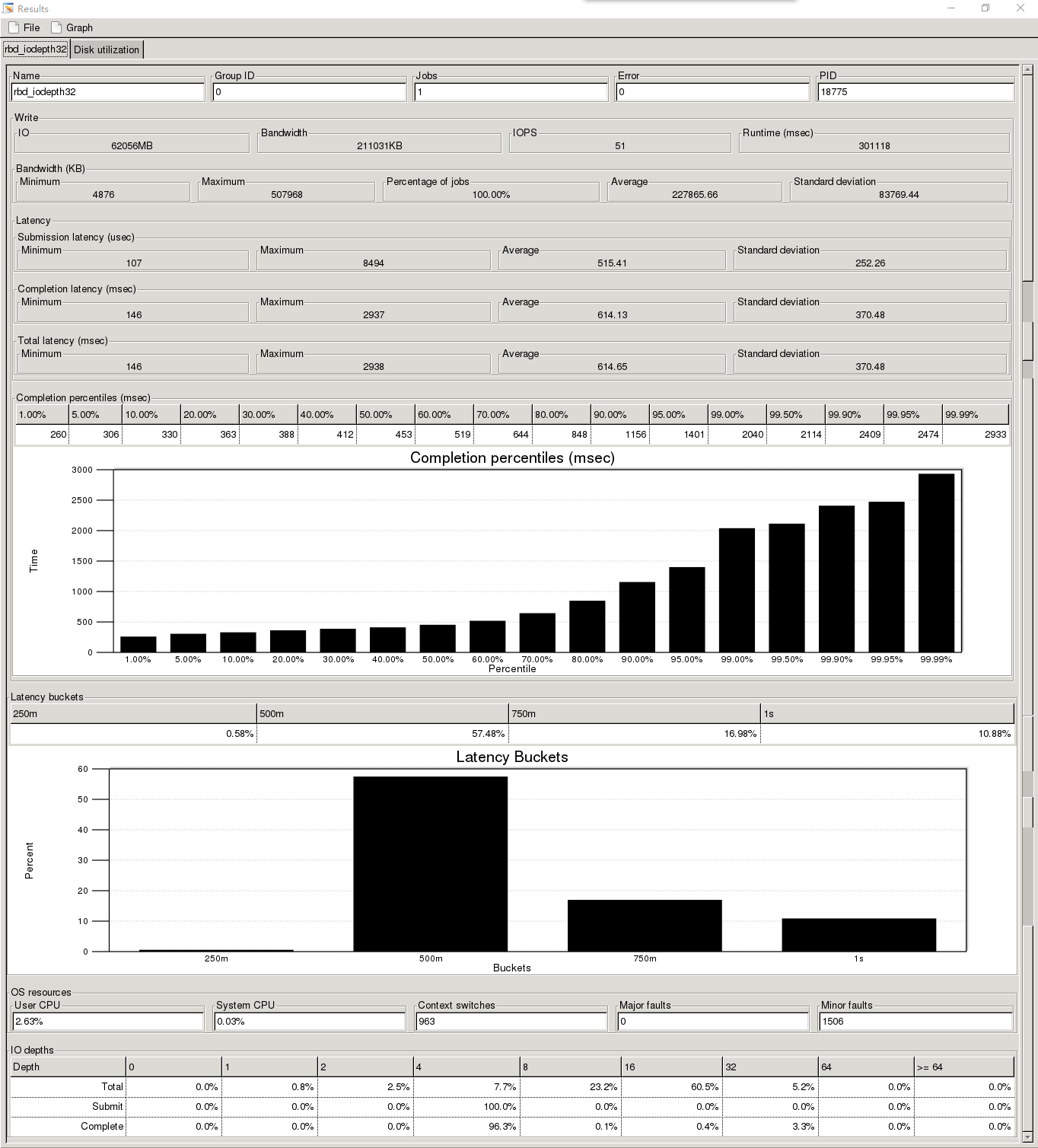
二、测试bluestore
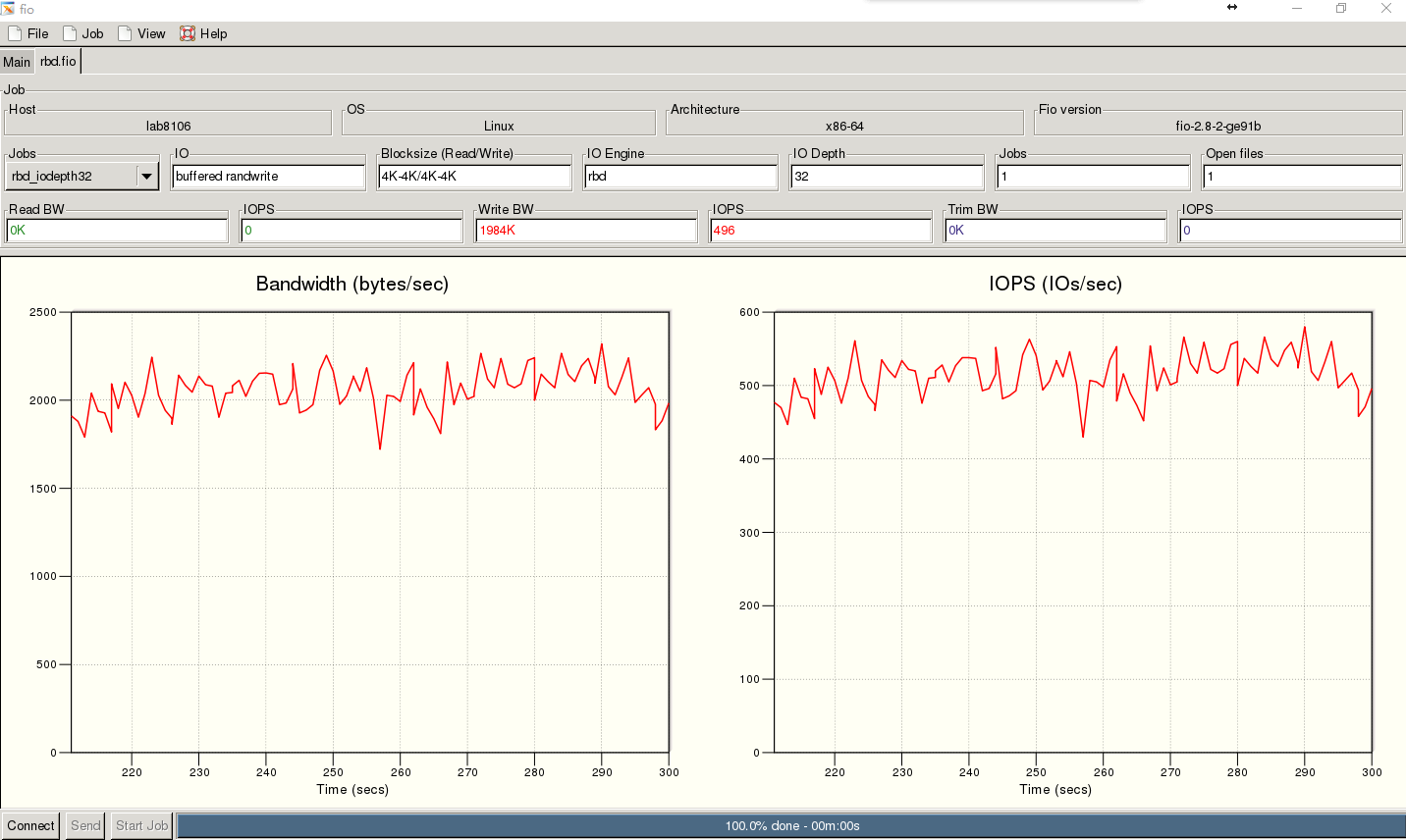
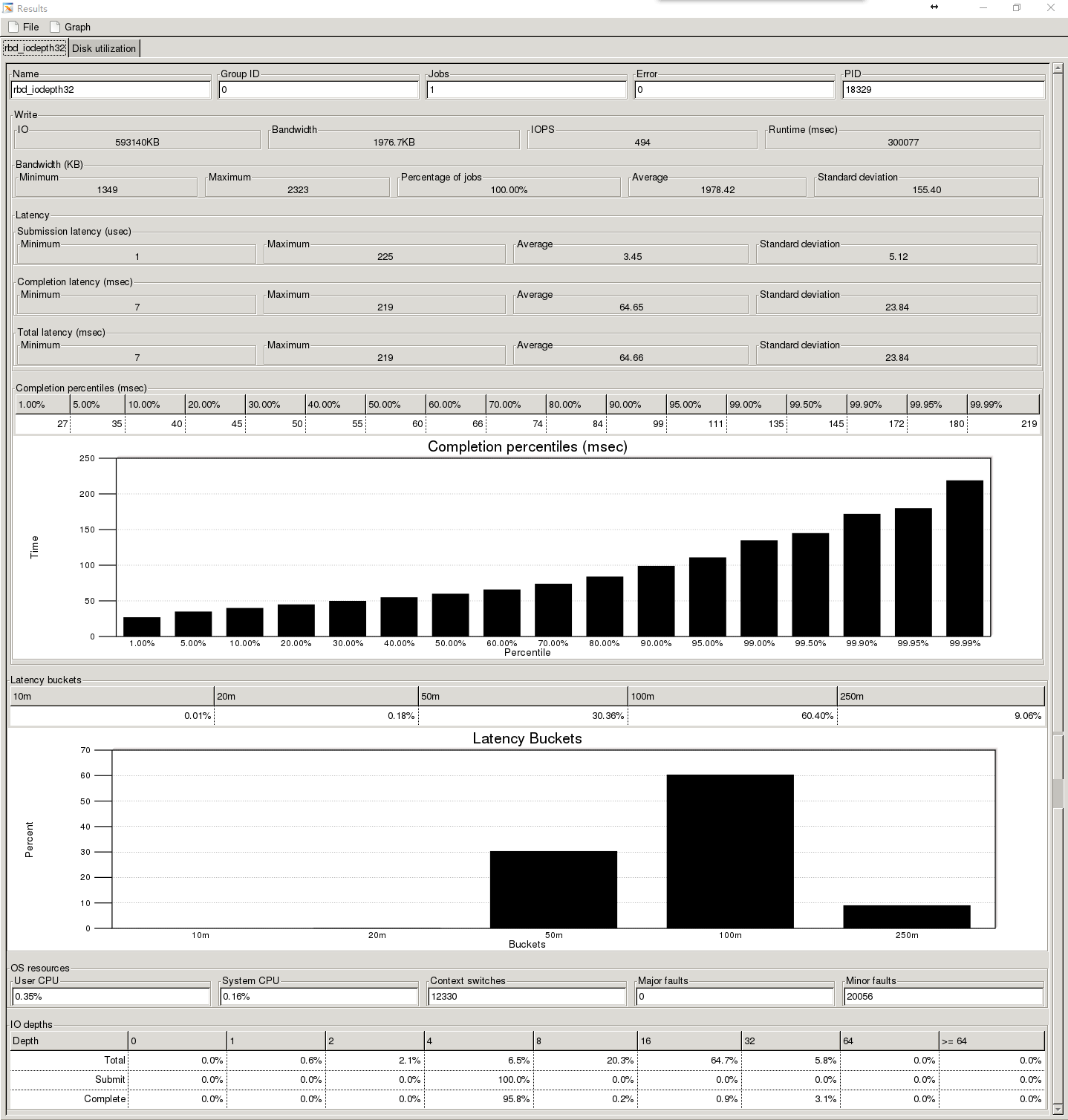
1、4K随机写200G的rbd测试时间300s
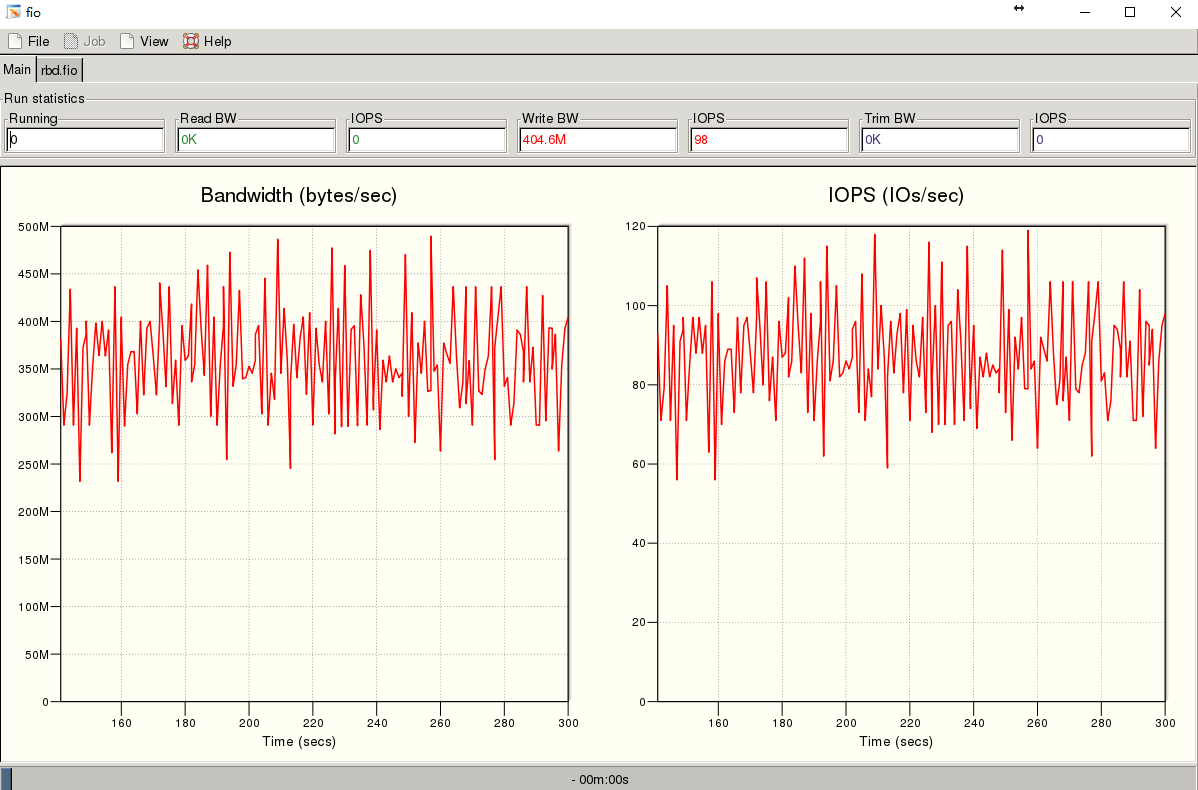
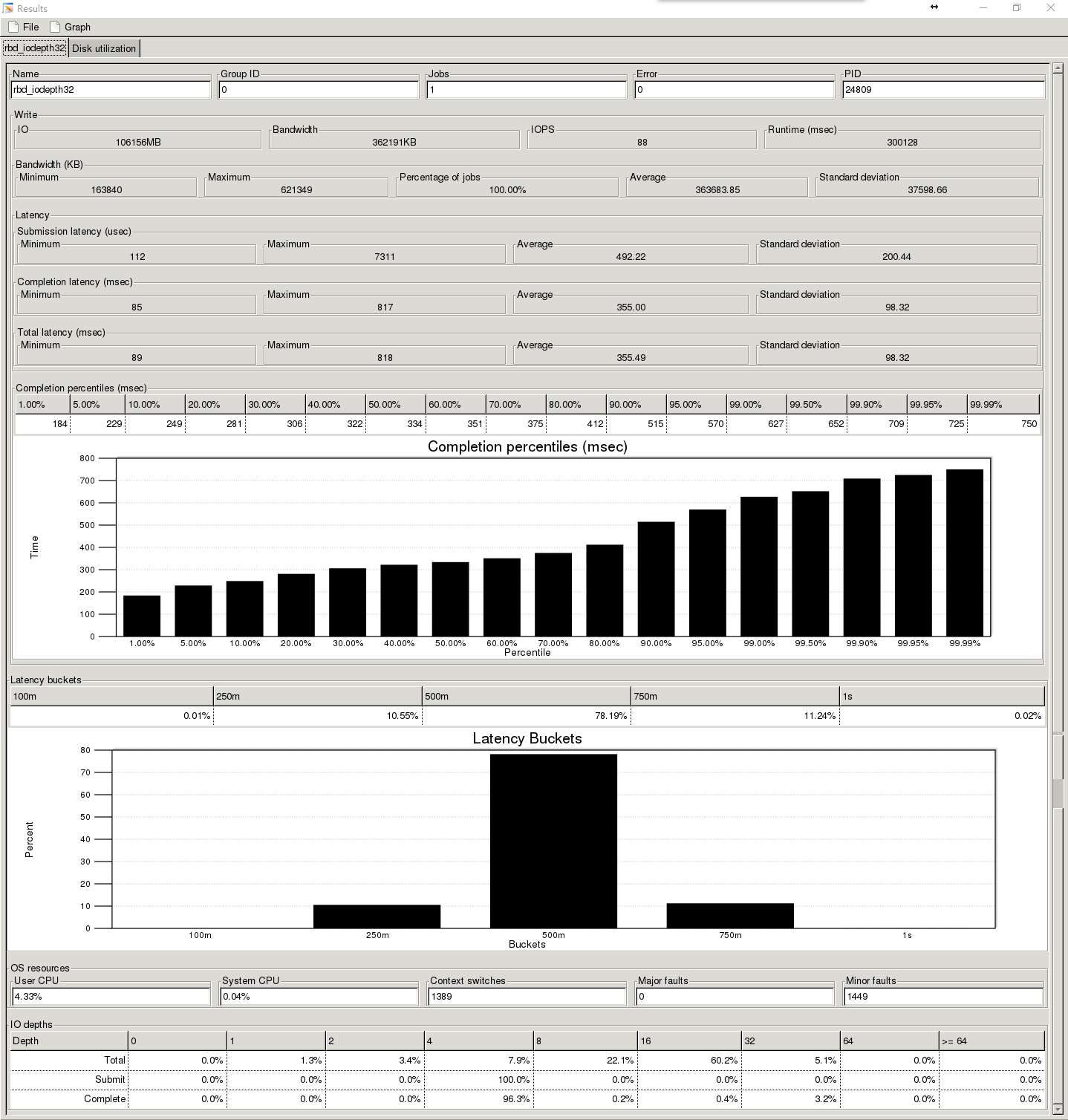
2、4M顺序写200G的rbd测试时间300s
以上为测试过程的数据记录,下面为对比的
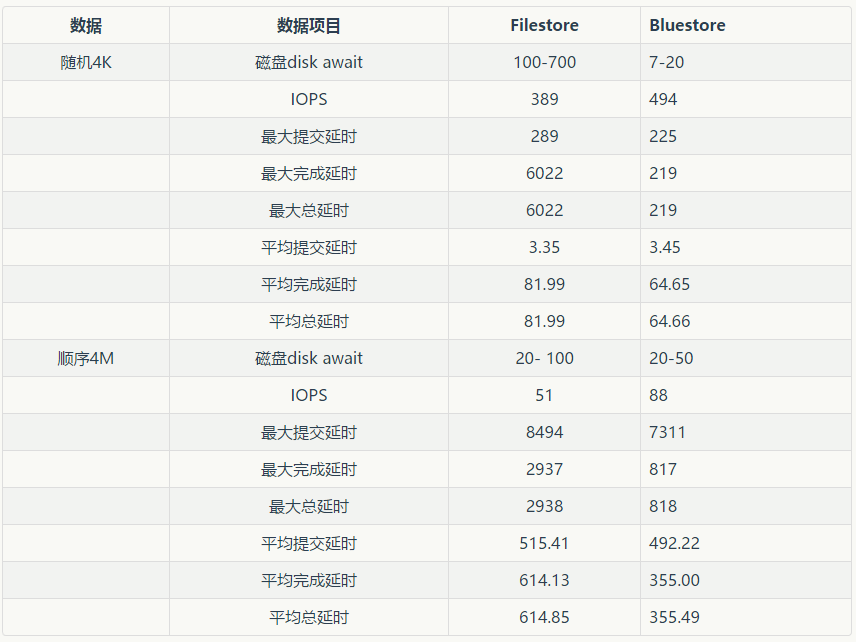
整个测试来看改进非常的大,数据的曲线比之前要平滑很多,延时也变得更小,但是还是开发阶段,估计bug还是很多,不可控因素太多,并且暂时还没有修复工具,作为对未来ceph发展的一种期待吧,肯定会越来越好
Ceph Bluestore首测
https://zphj1987.com/2016/03/24/Ceph Bluestore首测/